Find Particular Solution for Ax V W
Machine Learning & Linear Algebra
![]()
Linear algebra is essential in Machine Learning (ML) and Deep Learning (DL). It is not hard. You just need to bring yourself up to speed. I will skip fundamentals like what is a vector, and matrix and how to add and multiply them. I assume you still remember them. I will refresh the basic concepts quickly and cover some important topics in greater depth.
Distributive, associative & communicative
Basic matrix behavior:
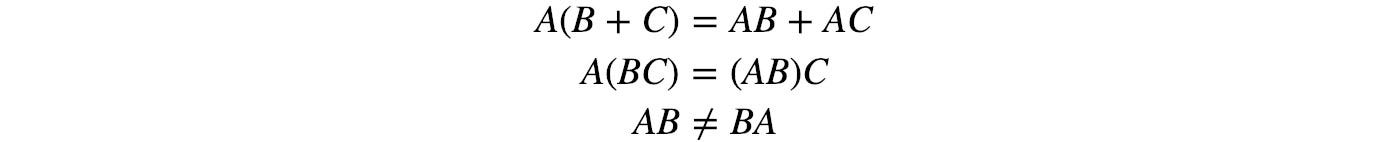
As shown in the last equation, matrices are not commutable.
Transpose
By convention, a vector x is written as a column vector. Here are the transposes of a vector and a matrix.
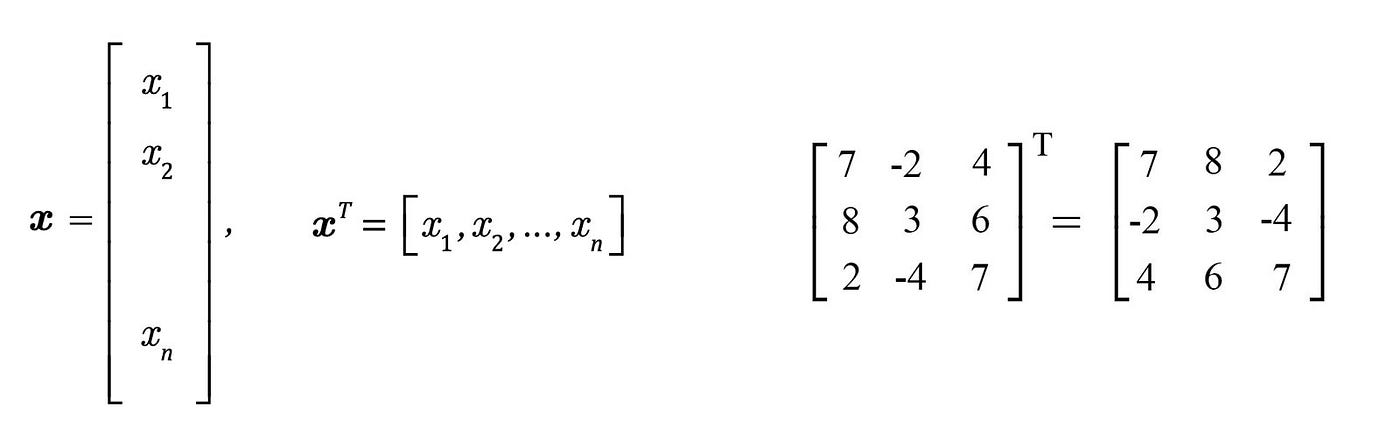
Properties
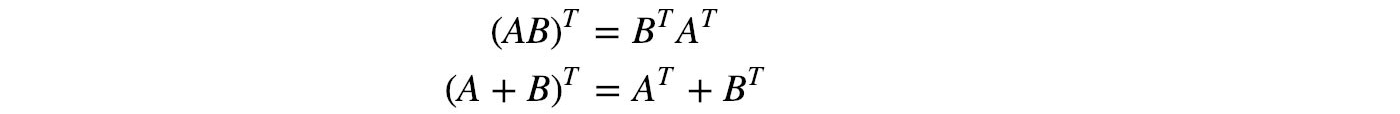
A matrix is symmetric if A = Aᵀ. It is called antisymmetric (skew-symmetric) if A = -Aᵀ.
Inner Product
The inner product ⟨a, b⟩ (or a・b) is a scalar function. The inner product for two vectors is defined as:
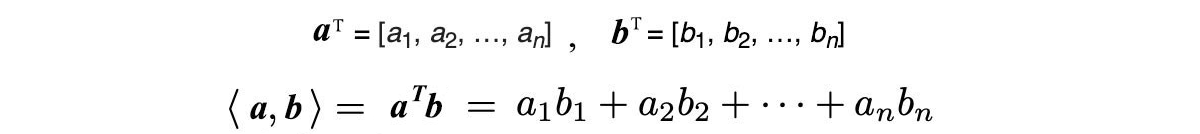
The transpose of any scalar value equals itself. You will see the following manipulation in many machine learning papers.
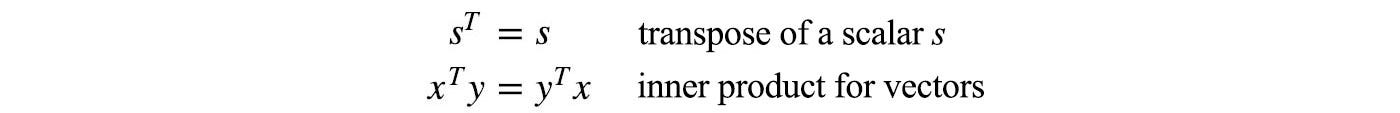
A unit vector is a vector with a unit length.
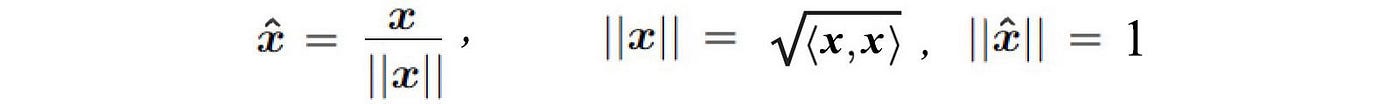
The angle between the two vectors u and v is
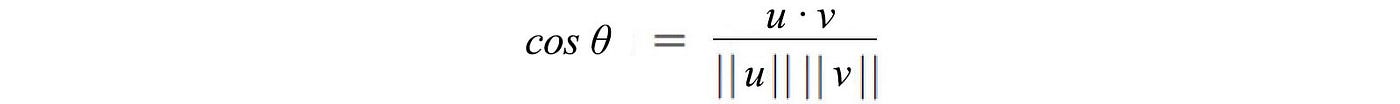
Vectors obey the following inequality
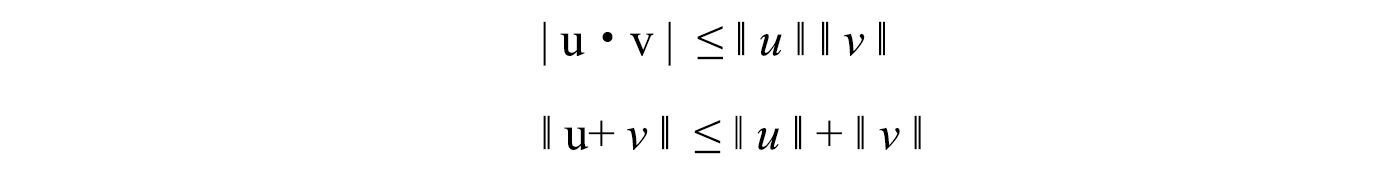
Properties
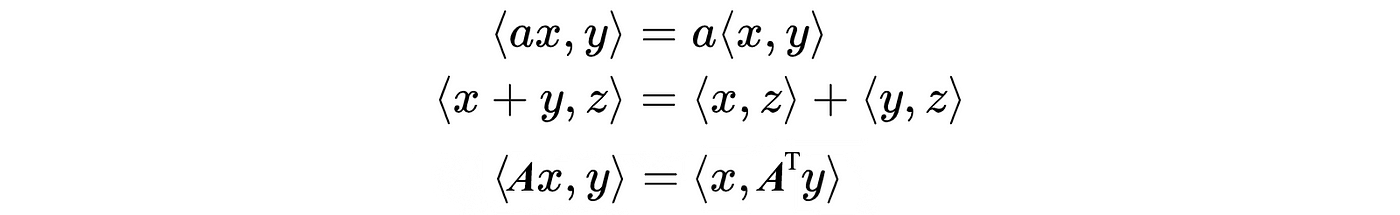
The last equation is important. Here is its proof:
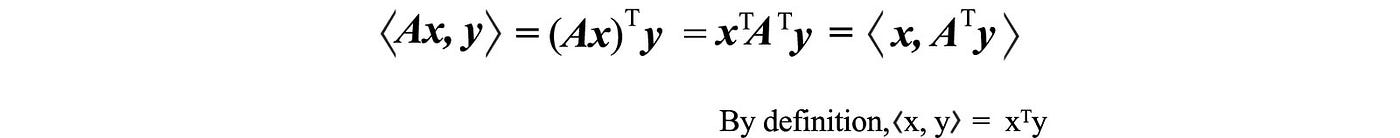
Outer product
Do not treat xᵀy the same as xyᵀ. The inner product xᵀy produces a scalar but the outer product xyᵀ produces a matrix.
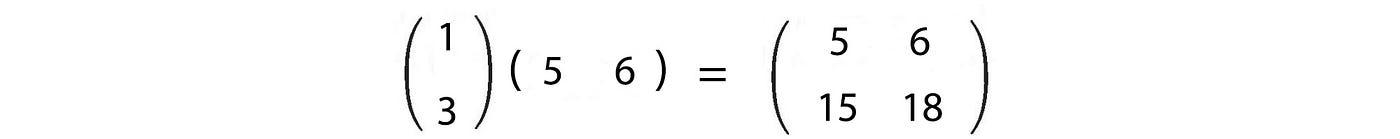
The multiplication of two matrices is the sum of the outer product of column i of A with row i of B.
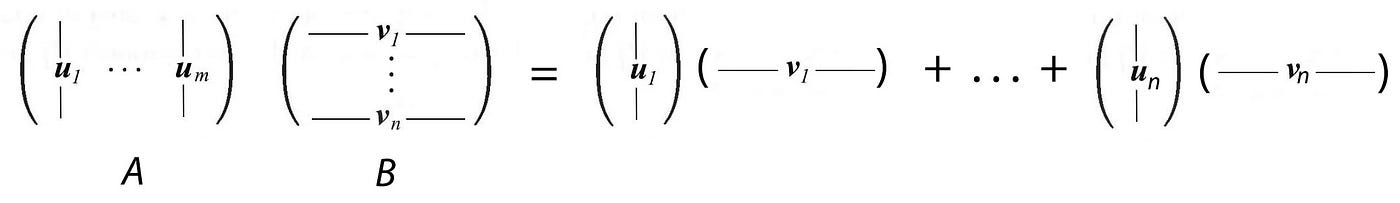
Example
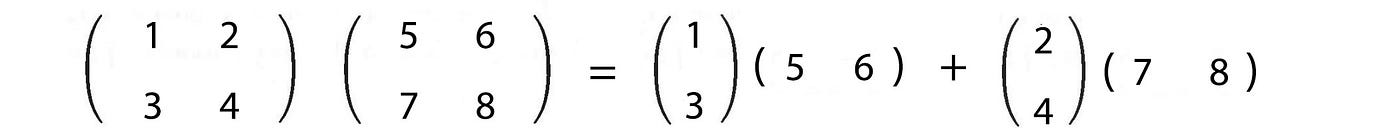
This perspective of matrix multiplication seems odd but becomes very important when we look into matrix factorization.
Derivative
In ML, we use matrices to store data. Objective functions and errors are expressed with matrices and vectors. To optimize a solution or to minimize an error, we need to know how to differentiate them. Let's define the notation for the derivative of a scalar y (f( x )) w.r.t. x as

Here is the notation we will use for differentiating a vector y w.r.t. x.
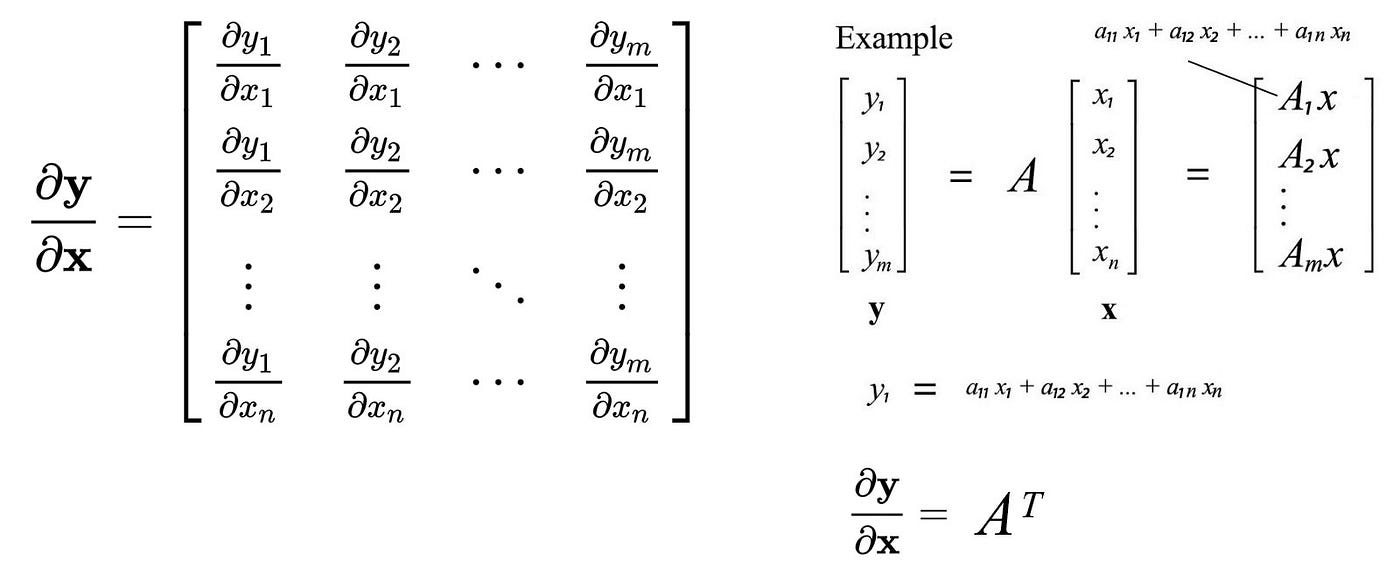
The notation above is called the denominator-layout notation. Let's calculate the derivative of vectors and matrices.


There are other notations. The numerator layout uses a column vector for the derivative of a scalar.
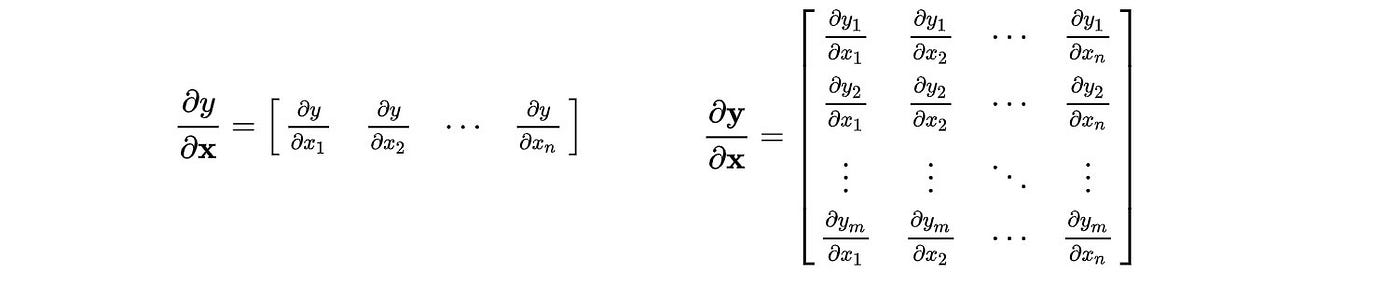
If this notation is used, the results of our previous equations need to be transposed.
Let's optimizes the mean square error of linear regression and apply what we learn.

Inverse
The matrix inverse of matrix A is defined as:
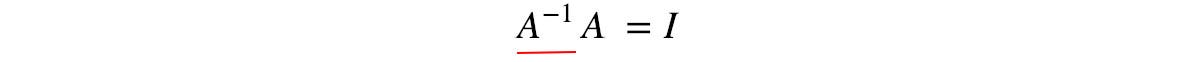
Properties:
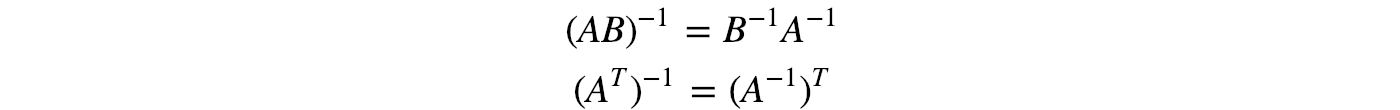
Note: The property above is true only if A and B are invertible. It is not true even when A is a non-square matrix. (the matrix inverse assumes A is an n × n square matrix.) To solve a system of linear equations Ax=b, we can multiply the matrix inverse of A with b to solve x.
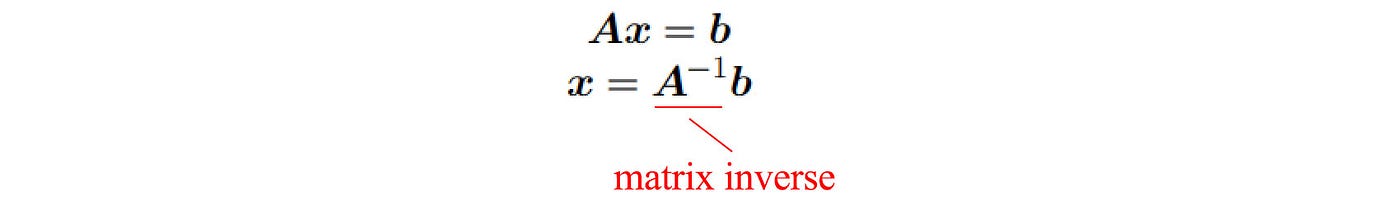
If A is not invertible, this method fails. We will need some other methods, like Gaussian elimination, to solve it.
We introduce the inverse above on the left side — left inverse. If it is introduced on the right side, it is called the right inverse.
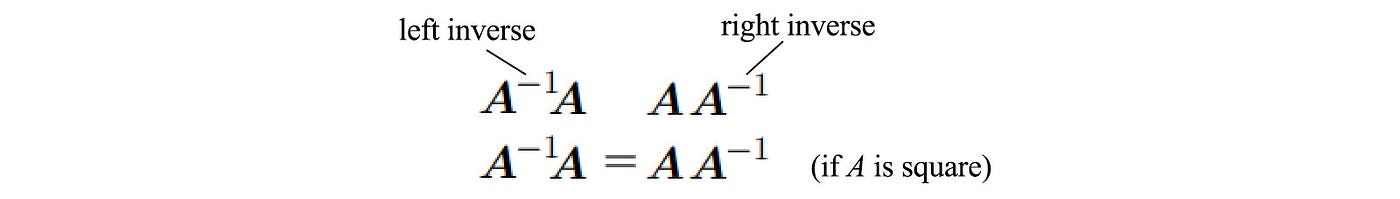
For a square matrix, both are the same and we just call it the inverse. As a side note, because matrices are not commutable, the concepts of "right" and "left" appear frequently in many terms.
However, even inverse seems to be everywhere in literature, we avoid inverting an arbitrary matrix in practice. In machine learning (ML), we deal with many sparse matrices — a matrix mainly composed of zero-value elements. The inverse of a sparse matrix is dense and less desirable because of space and computational complexity. In addition, inverting a matrix can be numerically unstable — a small imprecision or error in the input can trigger a large error.
Singular matrix
So what matrices are not invertible? A singular (degenerate) matrix is a square matrix that does not have an inverse. The following equations calculate the inverse of a 3 × 3 matrix.
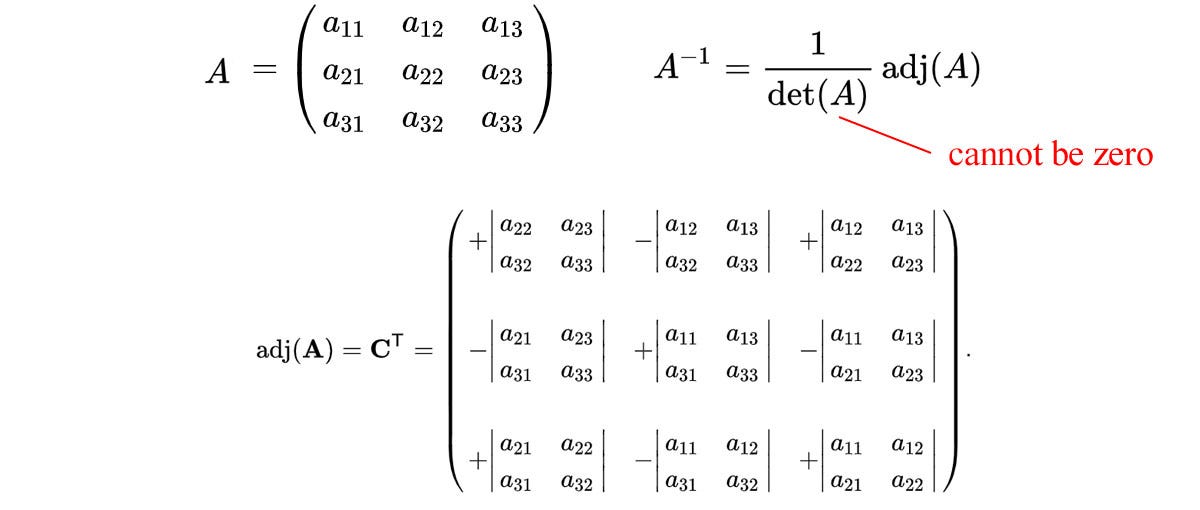
For the inverse to exist, the determinant cannot be 0. For example, the matrix below is a singular matrix.
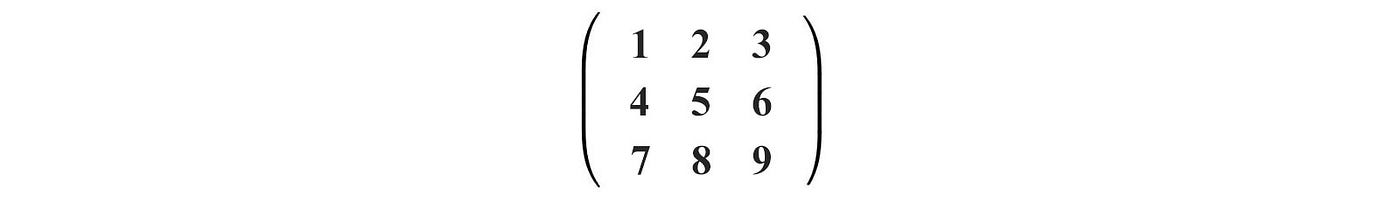
Its determinant equals 0. Therefore, it does not have an inverse.
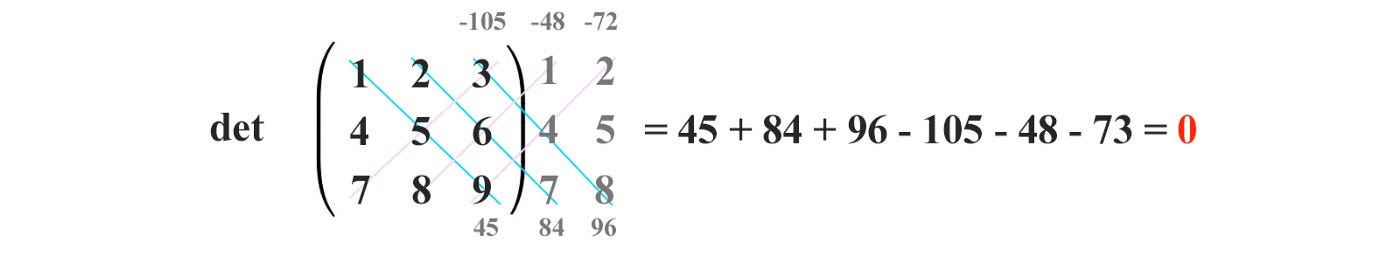
Row space & column space
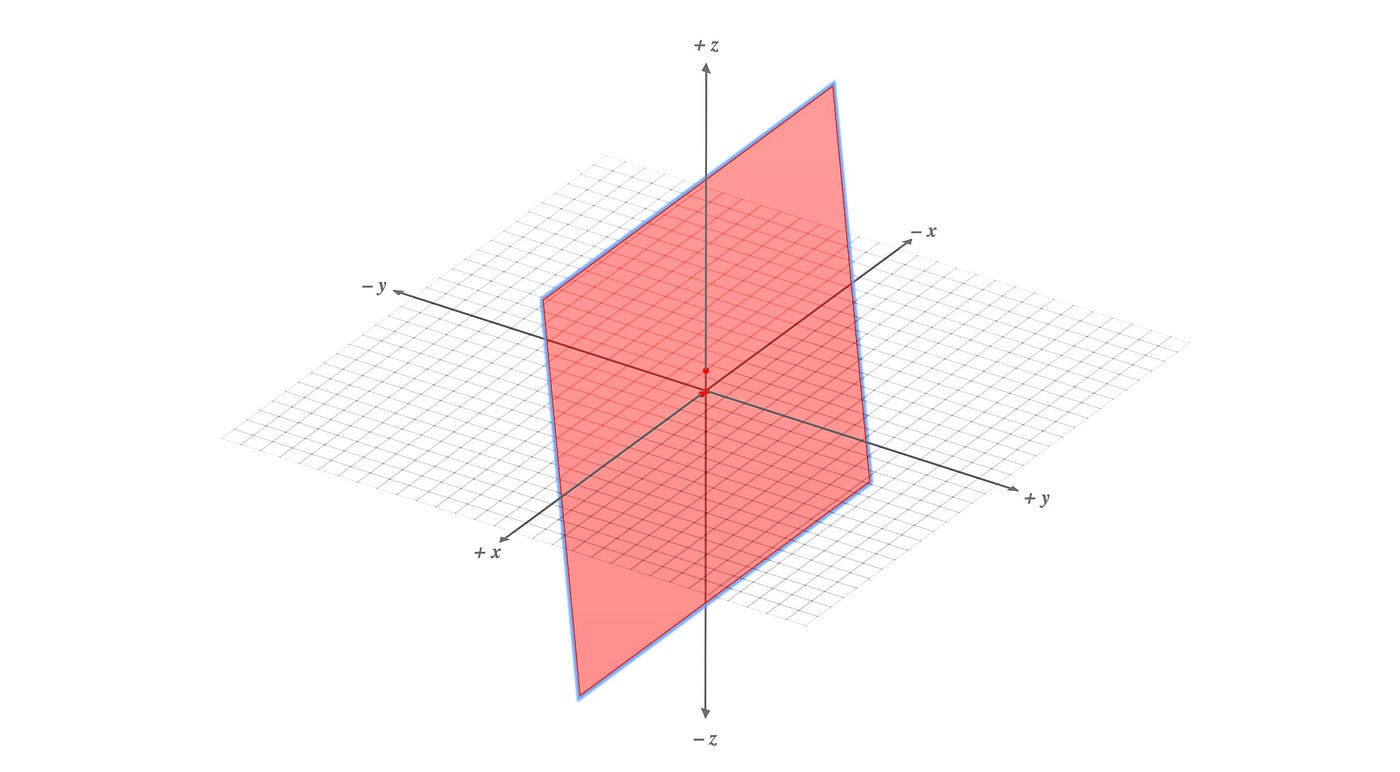
Vectors can be grouped to form a vector space. Rⁿ is a vector space containing all the n-dimensional real number vectors. Space can be divided into subspaces for further study. For example, R³ is a 3-D space and a plane is a subspace of R³.
Mathematicians love to create abstract concepts so one stone can kill two birds. By definition, if u and v are in a space, both u + v and cu (where c is a constant) must be in the same space. If not, they don't form a space. This definition works for the subspaces also.
This is a very abstract definition. It does not limit itself to vectors. Indeed, many objects including polynomial functions can form a space. For example, polynomial functions of any order form a space. Add two polynomial functions of x together remains to be a polynomial.
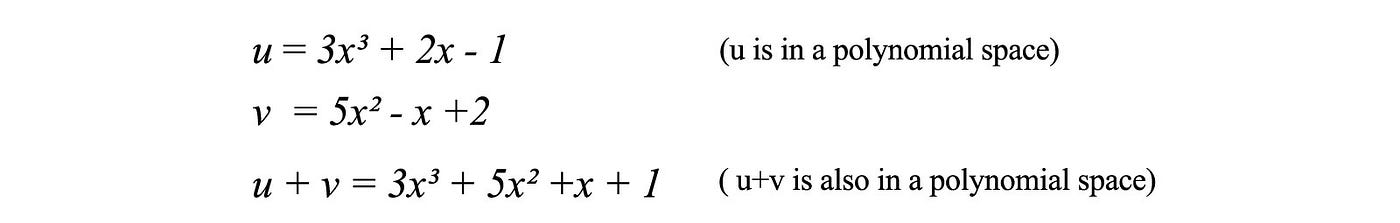
The linear combination of columns of a matrix spans a space called the column space.

If all the column vectors above are linear independent, the column space spans the whole 3-dimensional space. However, the column vectors above are linear dependent. The third column vector is a linear combination of the first two columns.

We can remove the third column vectors in representing the column space of A. Therefore, the column space of this matrix span a plane only.
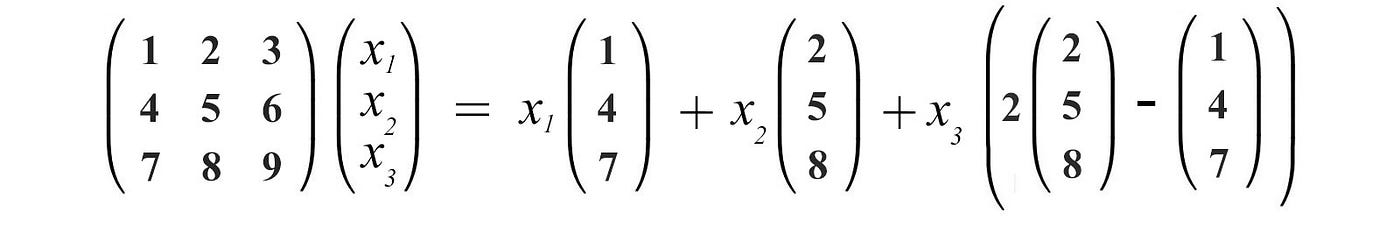
The concept that Ax is a linear combination of the column vectors of A is very fundamental. So, spend a few seconds to get used to this concept.
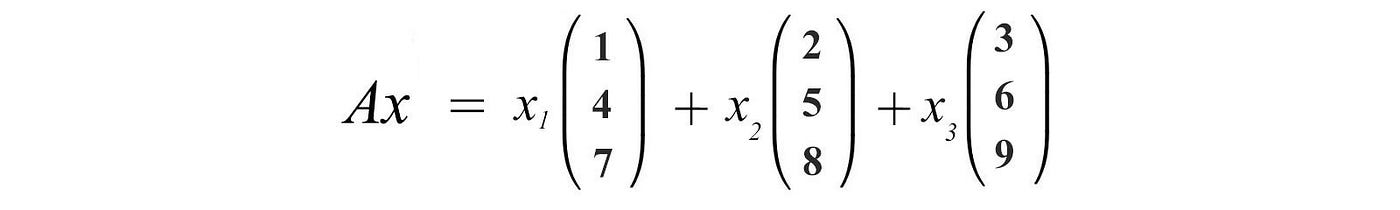
This equation is also presented in a more familiar form
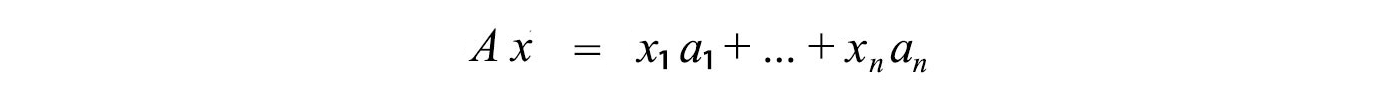
where a₁ to an span the column space of A (the basis for the column space).
Similar, rows form row vectors in creating a row space.

If we use the notation C(A) for the column space of A, we can transpose A and C(Aᵀ) represent the row space of A.
Linear dependency
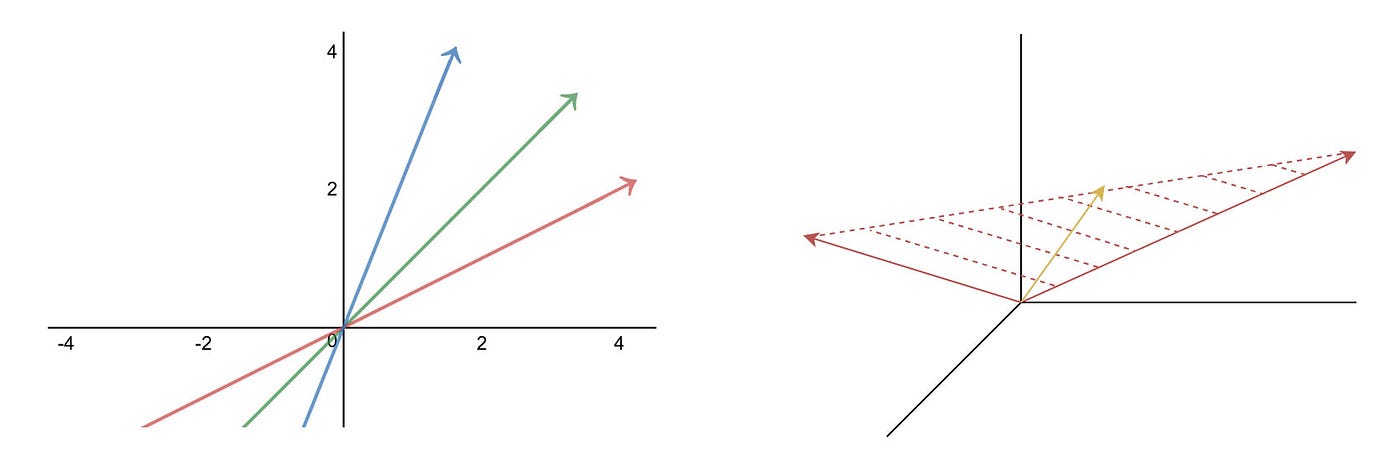
An n-dimensional space cannot have more than n linearly independent vectors. In the left diagram below, the vector in the green color can be expressed by the blue and the red vector. Two vector forms a plane in a 3-D space. Any vectors in the same plane, like the yellow vector below, is a linear combination of the red vectors.
Mathematically, for a set of vectors to be linearly independent, it fulfills
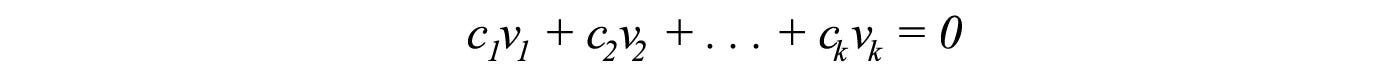
only if all the linear factors cᵢ are 0. In short, any vector cannot be expressed as a linear combination of others. In addition, the columns of A are linearly independent if the only solution for
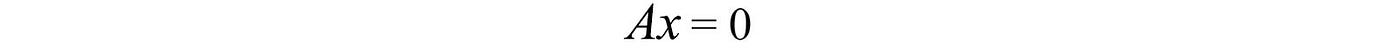
is
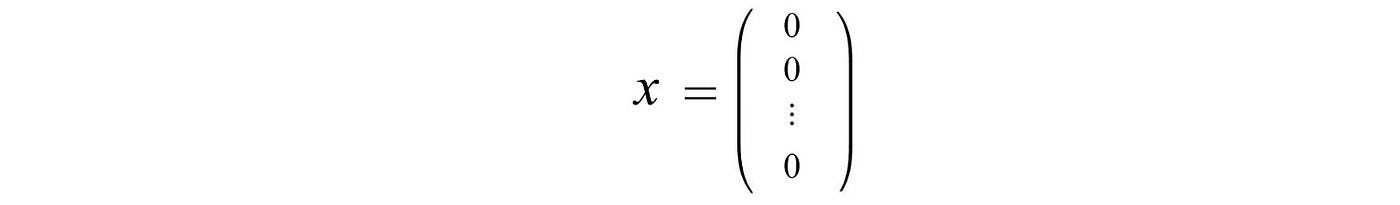
To have a solution other than 0, A needs to be singular. i.e.
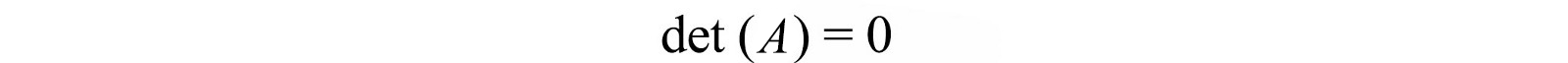
Otherwise, we can compute the inverse and v has exactly one solution equals 0.
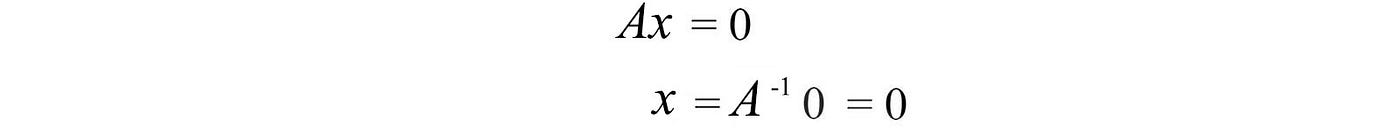
For Ax = 0 to have a non-zero solution, A is singular and det(A) = 0.
This becomes useful when we study the eigenvectors later.
Rank
Rank measures the linear independence of the columns/rows of A. It is the dimension span by these columns/rows. The rank of a matrix equals
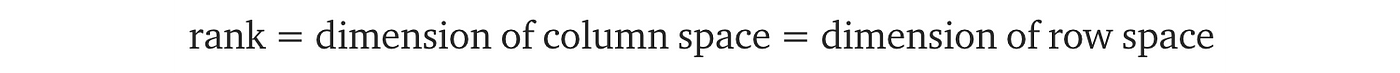
For any matrix, the column space and row space have the same dimension (rank). Therefore, the rank of a matrix can be calculated either from rows or columns. The following are the ranks for different matrices.
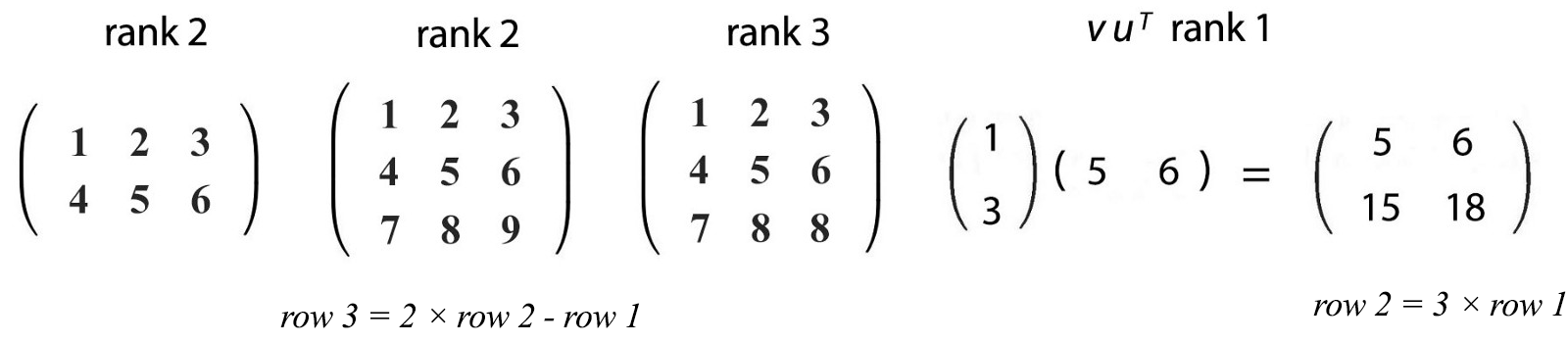
If a matrix is invertible, its inverse is unique. There will be exactly one solution for x=A⁻¹b. However, for a square matrix, if columns/rows are linearly dependent, the matrix is singular and not invertible.
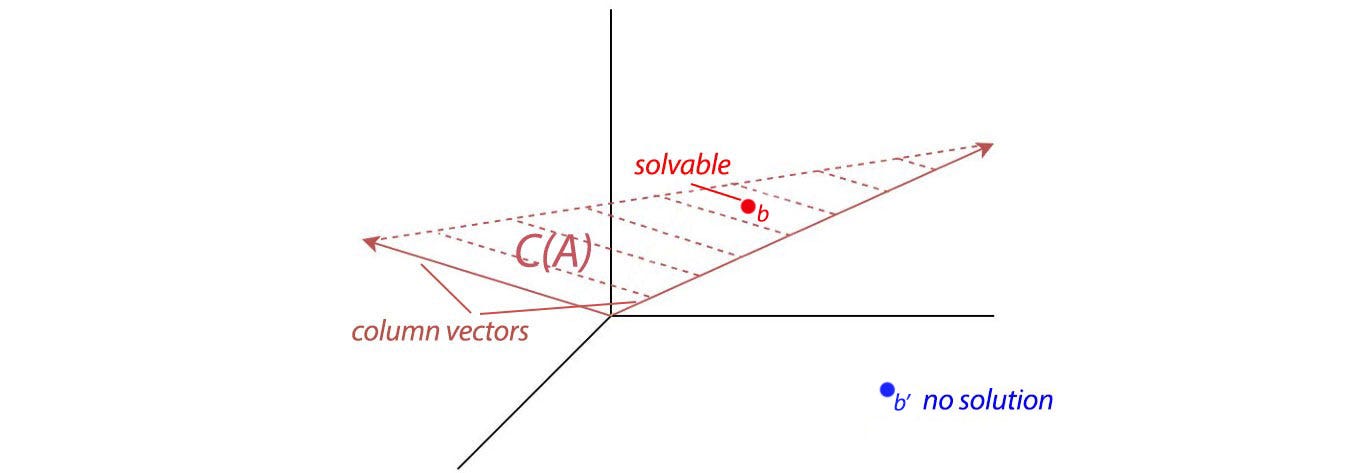
In general, for any matrix, the rank of A determine the linear dependency. From there, we can determine whether we have a unique solution. The figure below demonstrates how we represent a system of linear equations in the matrix form and its number of solution.
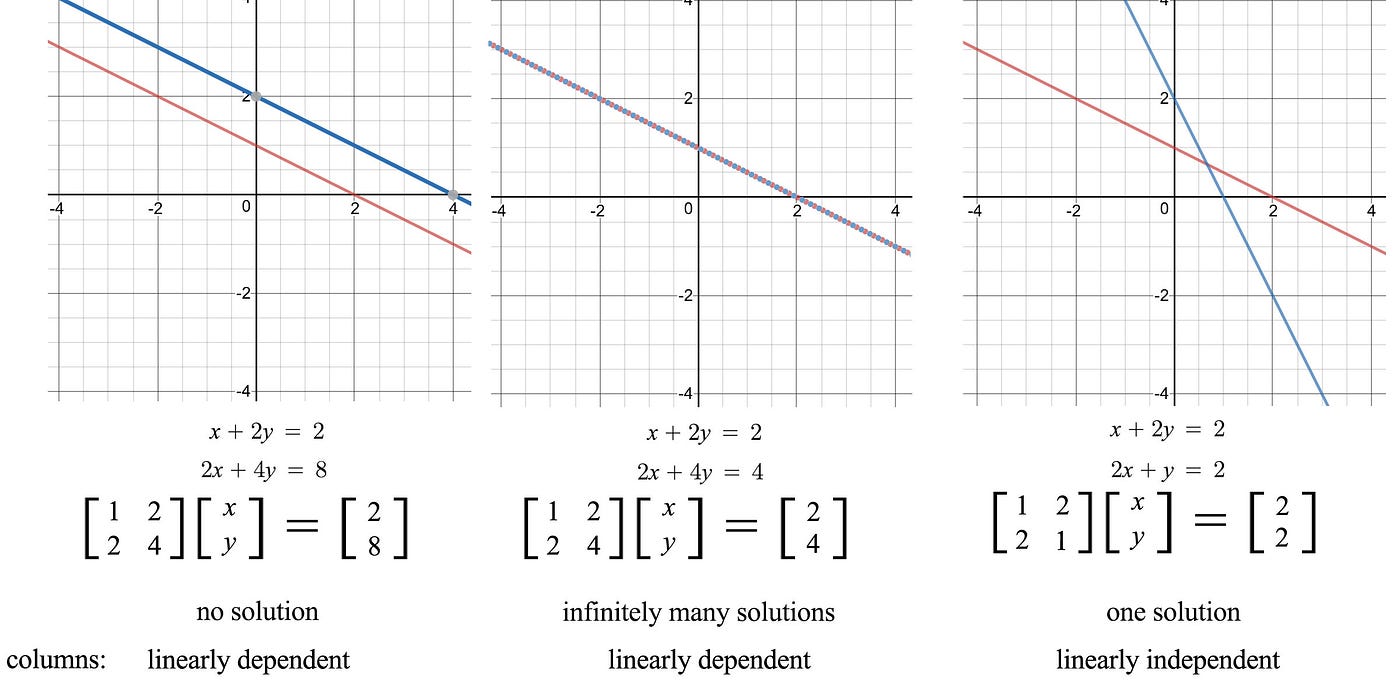
It has zero solution if b is not in the column space of A. i.e. the linear combination of columns in A cannot reach b.
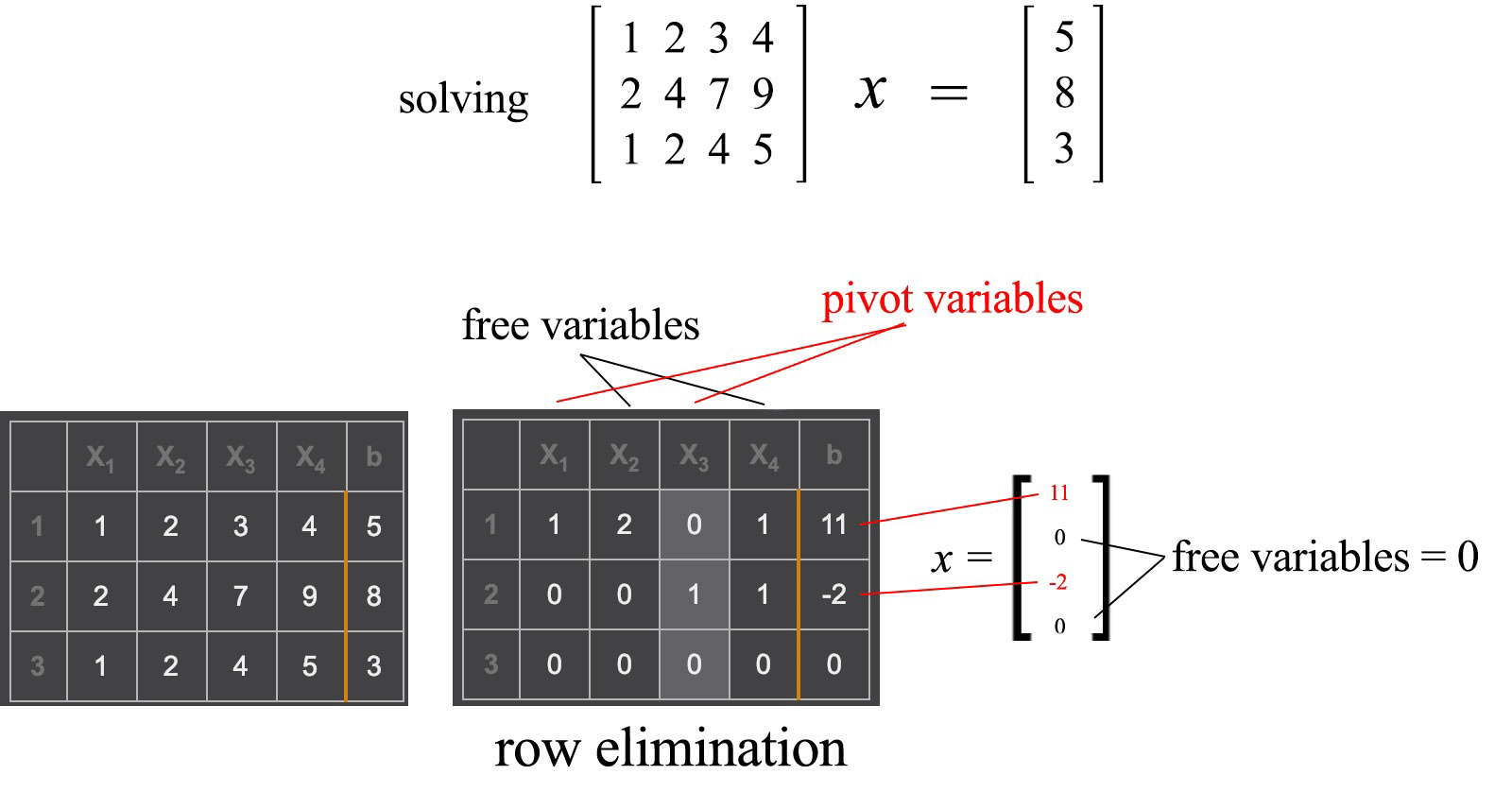
Gaussian elimination & back substitution
As discussed before, we rarely compute the inverse of A to solve x for Ax=b. One most common method is Gaussian elimination and back substitution. Many people already know how to solve linear equations through this method. So I will go through it quickly and introduce some key terms. To solve,
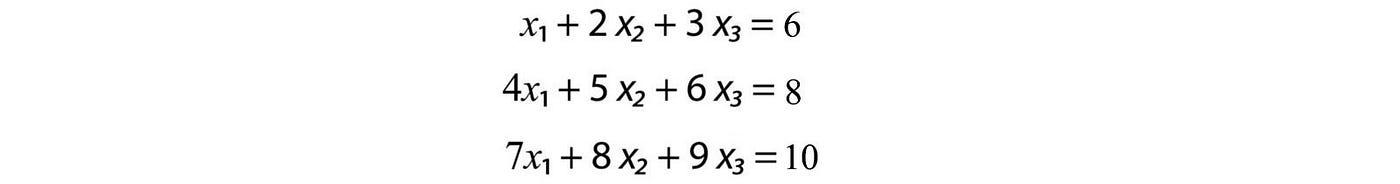
We apply elimination to create leading zeros for row 2 and row 3 in the x₁ column. Once we are done with the column for x₁, we repeat the process for x₂ and x₃.
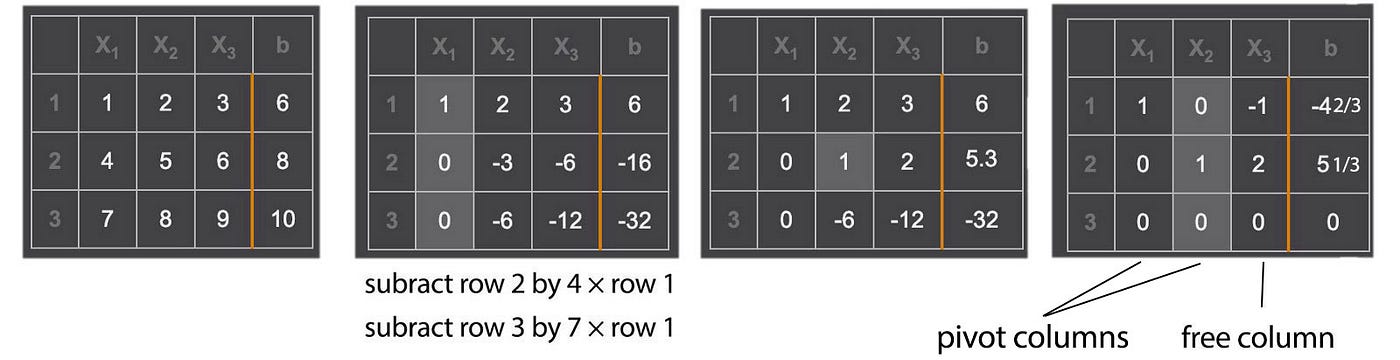
This matrix A can be eliminated into two rows with non-zero leading values. These two non-zero values are called pivots.

The rank of a matrix equals the number of pivots. After the elimination, we are left with two meaningful equations only. If an n × n matrix has less than n pivots, the matrix is singular. Excluding column b, the bottom row(s) will have all zeros.
The variables corresponding to a pivot in its column are called the pivot variables. The other variables are called free variables which can take infinitely many values. In the example above, we have two pivot variables (x₁, x₂) and one free variable x₃. After the elimination steps, the matrix associated with the variables x , forms an upper triangular matrix.

To solve Ax=b, we perform back substitution. Start from the bottom row and resolve one variable at a time from the bottom to the top.

If we set the free variable x₃ to 0, one particular solution will be
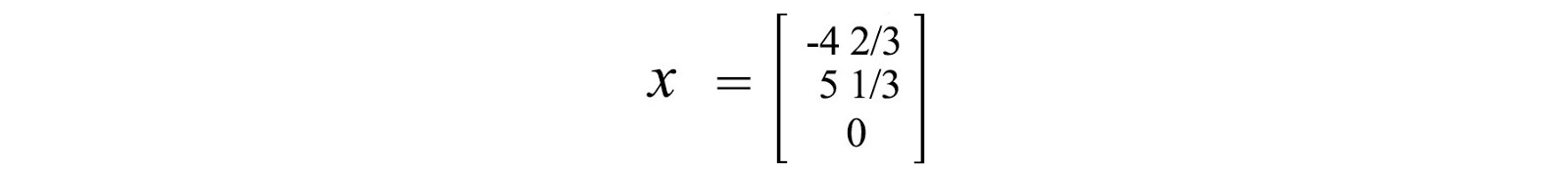
Let's solve another example using pivots. After the row elimination, we use the non-zero values in column b to set those pivot variables and then, set all free variables to 0. This becomes the solution for x.
Consider Ax=b where A is an m × n matrix with rank r and x has n components. After row elimination, excluding the column b, the matrix will have m - r all zeros rows.

If any all zero rows have b ≠ 0, it has no solution. We cannot conclude 0=2 in the right diagram above. The linear equations are conflicting with each other. If the rank r is less than n, x span n - r dimensions. In other words, if we have r linearly independent equations to solve n variables in x, x will have n - r degrees of freedom as long as there are no conflicts in the equations.
Gauss-Jordan Elimination
The method we used is called Gauss-Jordan elimination. Here is an example of a non-singular matrix.
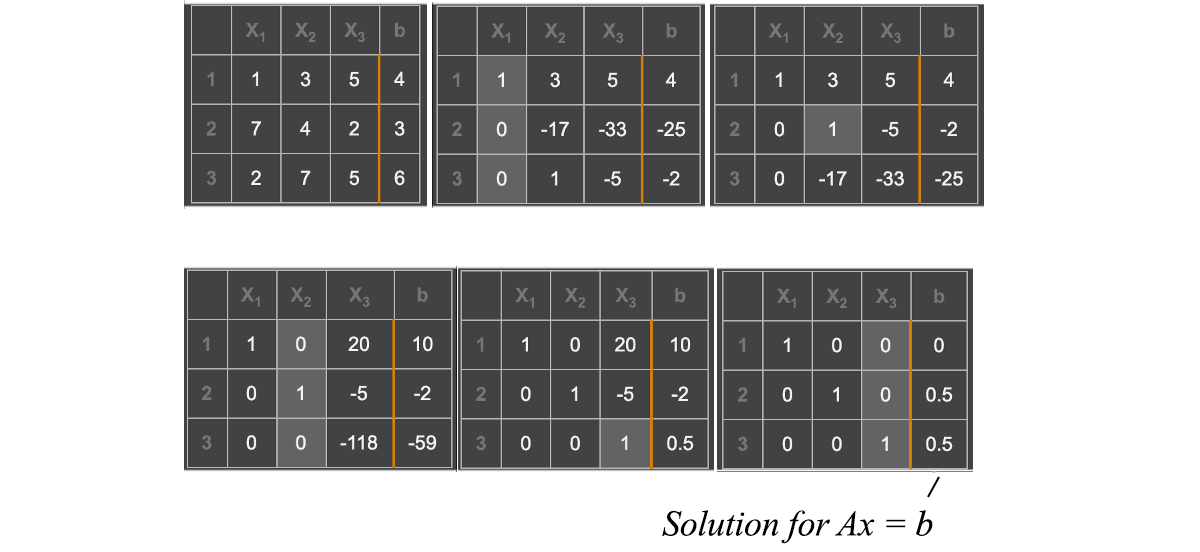
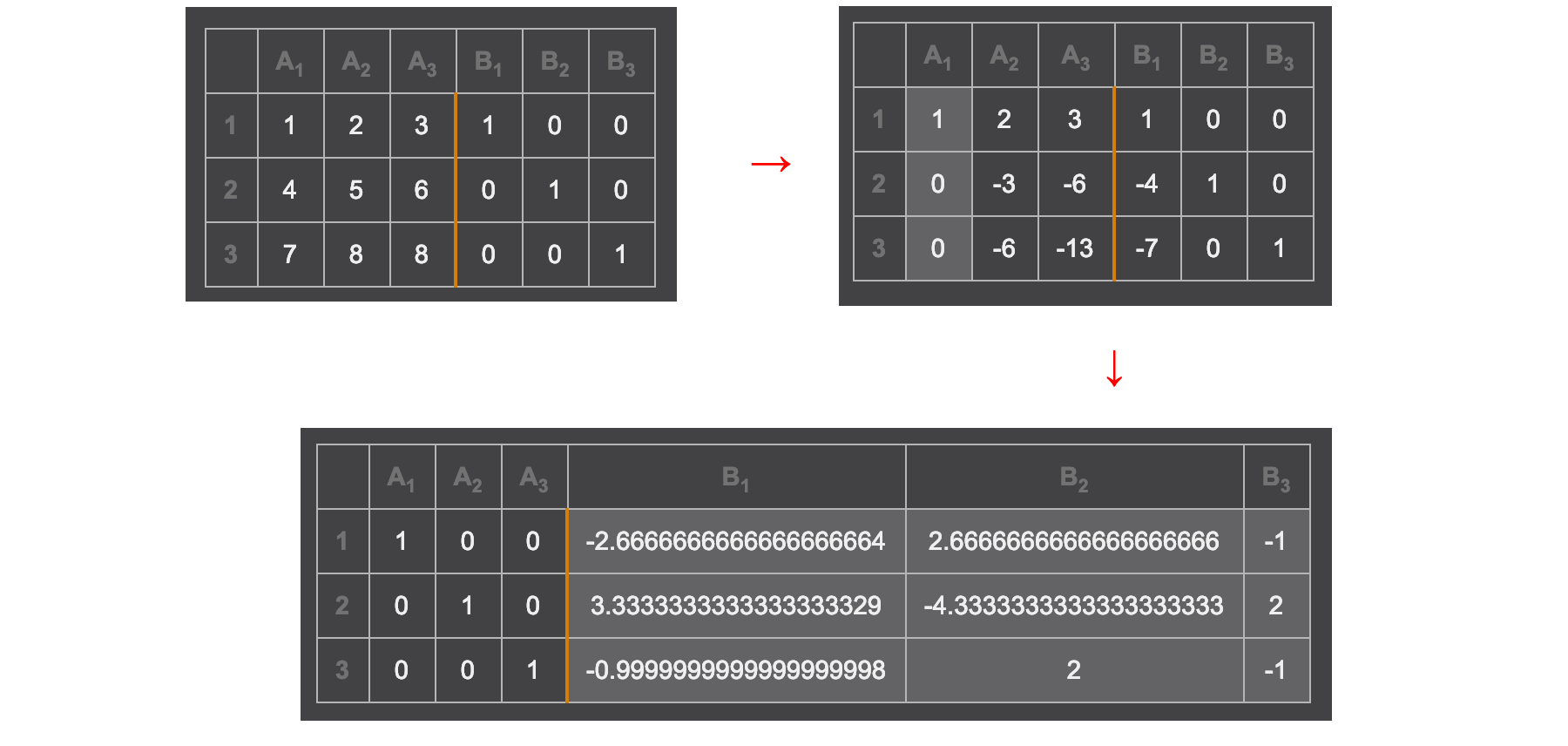
To find the inverse of A, we can replace b with an n × n identity matrix I. After the elimination, the columns holding the original identity matrix hold the inverse of A now.
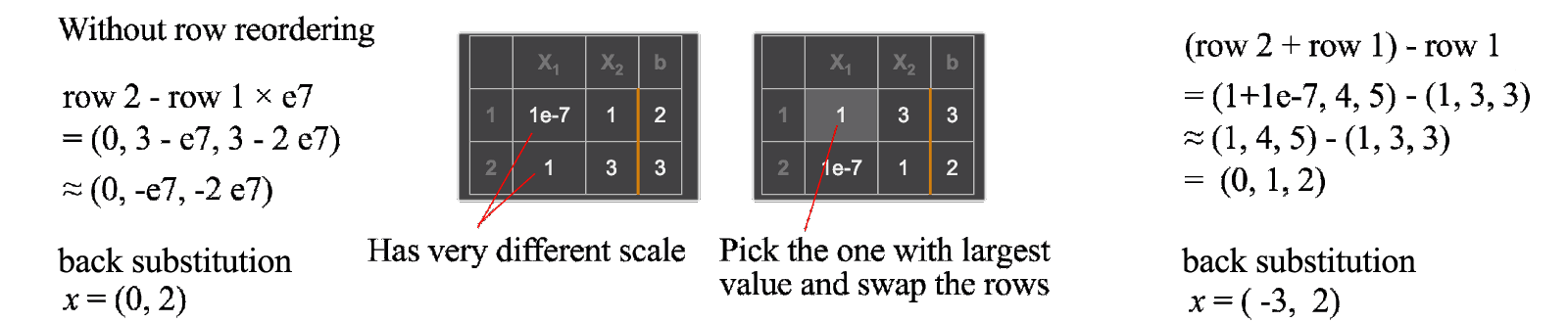
Computation has limited precision. When dealing with linear algebra, this is particularly important. In addition, we want the computation to be fast. We are blessed with libraries that handle the dirty work for us. So we will be brief here.
- Row exchange. With some clever exchange of rows, the row elimination and back substitution will be less vulnerable to rounding errors. Before a row elimination, if there is a huge difference in the scale of coefficients, we swap the top row with the underneath row that has the largest leading value. Without the reordering, the solution can be way off. Sometimes, rescaling a row may help also.
- Promoting & preserving the spareness of a matrix reduces the number of operations because we can ignore multiplying zero with any number. In matrix manipulation, we prefer the non-zero value to be located on a narrow band along the diagonal of a matrix.
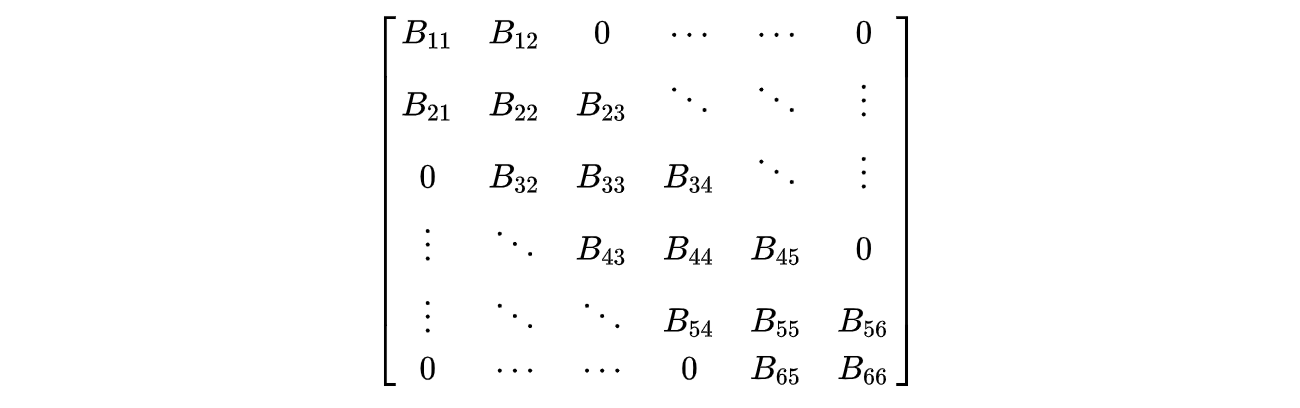
Nullspace & left nullspace
We have introduced the row space and column space. There are two more subspaces that are important. The space span by x below is called the nullspace of A, with notation N(A).
It contains all the solutions for Ax=0. It contains at least x=0. Multiplying the row vector of A with x (the inner product) equals 0.
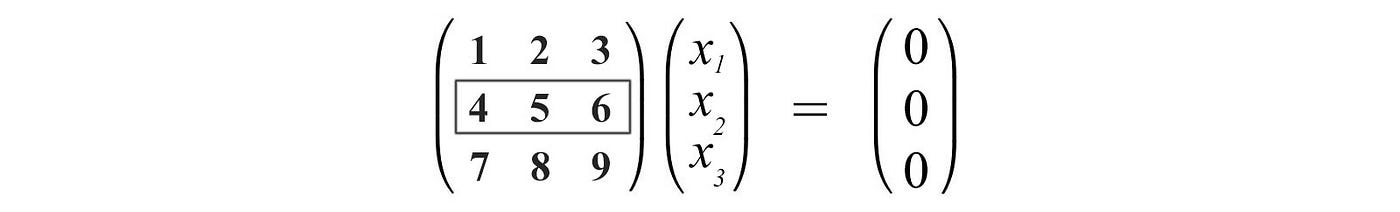
Therefore, any vectors in the row space are perpendicular to the nullspace. i.e.
The row space of A is orthogonal to the nullspace of A.
This matrix below has a rank of 2.

The column with the pivot variable is called the pivot column and one with the free variable is the free column. The number of free columns equals the number of columns minus the rank. As shown below, the corresponding free variables are x₂ and x₄.
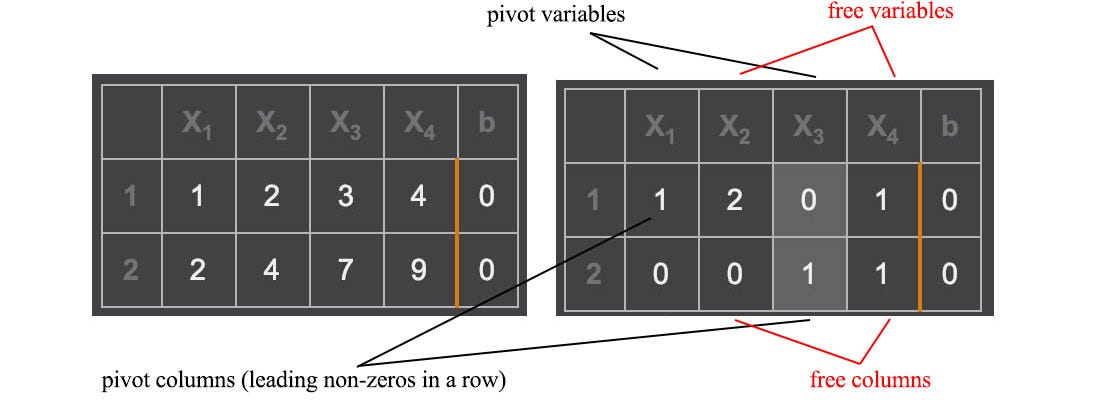
To solve Ax=0, we set each free variable to 1 with other free variables to 0 one at a time. With two free variables, we can derive two particular solutions.
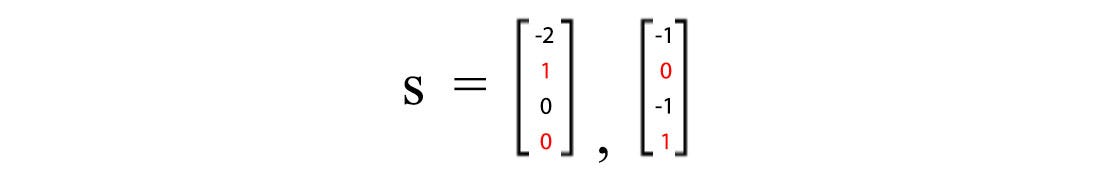
The complete solution for Ax=0 will be any linear combination of the particular solutions which form the nullspace with a rank of 2. As shown before, if columns in A are linear independent, the nullspace contains vector 0 only. Similarly, there is a left nullspace N(Aᵀ) which is orthogonal to the column space, i.e. Aᵀx = 0. Row space, column space, nullspace, and left nullspace form four fundamental subspaces from matrix A.
Complete solution for linear systems
Previously, we just find one particular solution for Ax=b . It can have infinitely many or none if A is singular. Let's find a complete solution now.
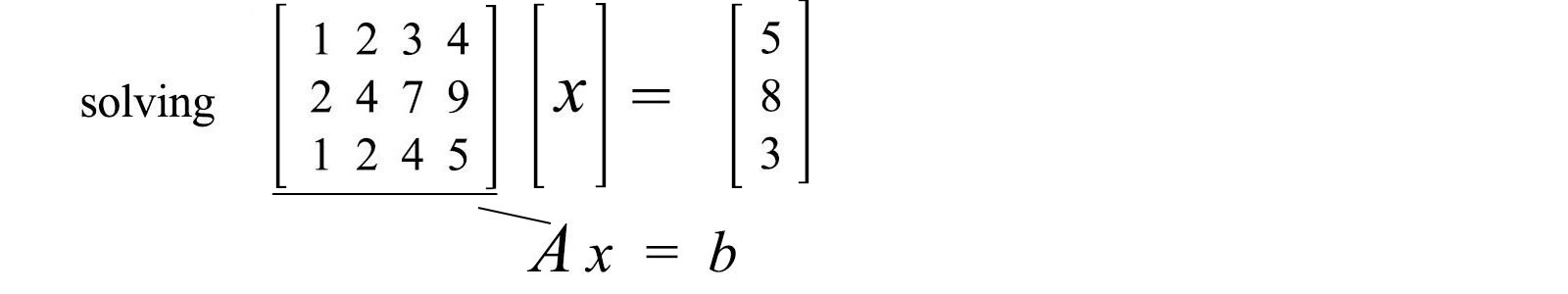
First, find a particular solution first.

Next, find the solutions for Ax=0 . A has a rank of two and therefore, we can find 2 (4 – 2=2) independent solutions.

The complete solution is the particular solution pluses any linear combination for the solutions of Ax=0.
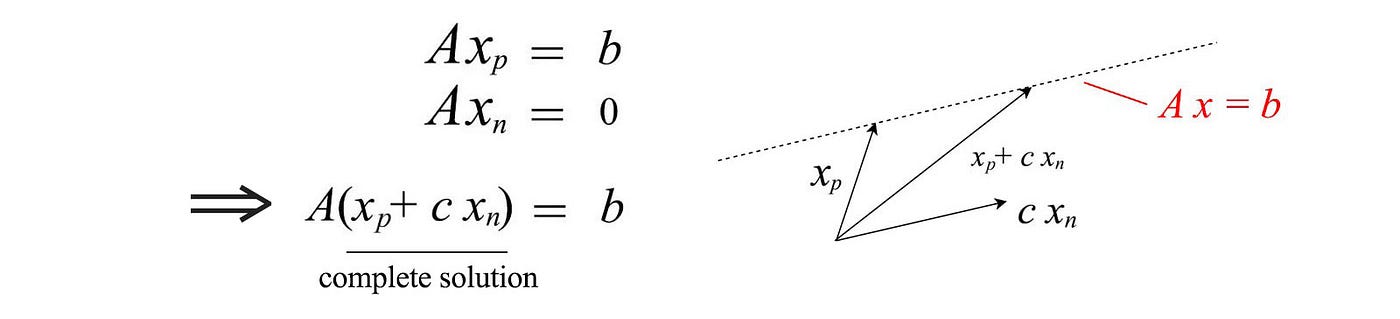
Graphically, this is the dotted line above for a 2-D example. The equation below is the complete solution for our example where cᵢ is constant.
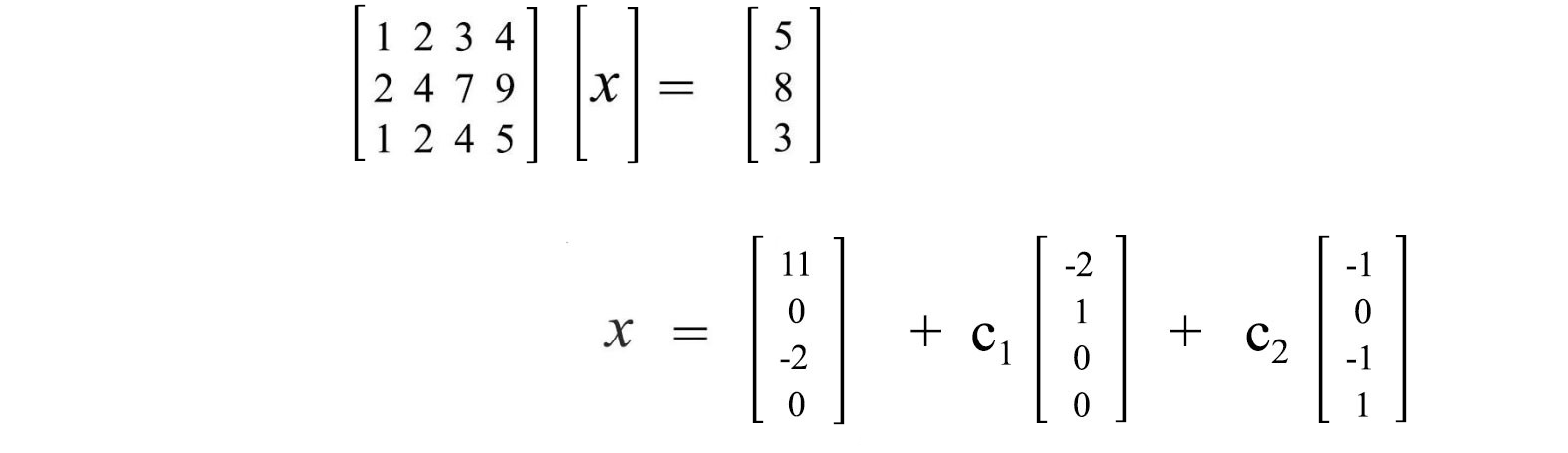
Orthogonal & Subspaces
Two vectors are orthogonal if their inner product ⟨x, y⟩ equals zero.
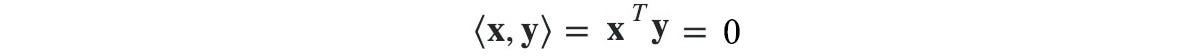
If they are 2-Dimensional or 3-dimensional vectors, they can be visualized as perpendicular to each other. We love zero in computer science because we can ignore many of its operations. Hence, we like to have vectors to be orthogonal to each other.
If orthogonal vectors have unit lengths, they are called orthonormal. Two subspaces are orthogonal to each other if any vectors from each subspace are always orthogonal to each other. In 3-D space, the x-axis and y-axis are two subspaces that are orthogonal to each other. However, not all vectors perpendicular to x-axis belong to the y-axis. It can be any vectors on the yz-plane. One subspace is orthogonal complement to another subspace if any vector perpendicular to one subspace must belong to the other subspace. Combining one vector from each subspace reconstruct the Rⁿ space. If one orthogonal complement subspace has a dimension k, the other subspace must have a dimension of n - k.
Column space, row space, nullspace, and left nullspace forms four fundamental subspaces from the m × n matrix A.
- column space: C(A)
- row space: C(Aᵀ)
- nullspace: N(A)
- left nullspace: N(Aᵀ)
The relationship for these subspaces are:
- Column space and row space have the same dimension & rank.
- The rank (r) of A equals the rank of the column space and row space.
- Row space is orthogonal complement (⊥) to nullspace.
- Column space is orthogonal complement (⊥) to left nullspace.
- Row space has r dimension, null space has n - r dimension.
- Column space has r dimension, left nullspace has m - r dimension.

Let's do a recap. In solving x for Ax=b, it is not solvable if b is not in the column space of A. And the particular solution of Ax=b is in the row space. The solution for Ax=0 is in the nullspace. The complete solution is formed by adding a particular solution and any linear combination of solutions from the nullspace.
Orthogonal matrix
If all the columns/rows of a square matrix A are orthonormal to each other, A is an orthogonal matrix which obeys
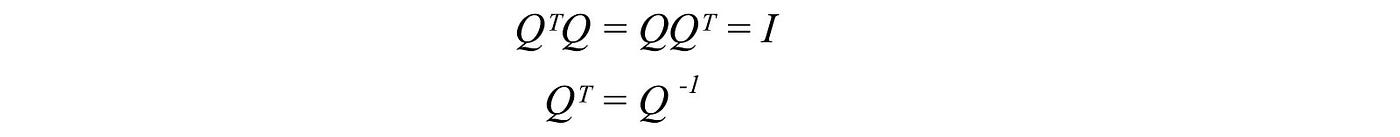
It is because if Q composes of columns q₁ to qn which are orthonormal to each other, the inner product ⟨ qᵢ, qⱼ⟩ equals 1 if i = j, otherwise 0. Therefore, QᵀQ = I. The equation Qᵀ = Q⁻¹ is very important. Computing an inverse is usually hard but not for the orthogonal matrix. Therefore, if we can factorize a matrix into orthogonal matrices, that will be great news. For a symmetric matrix, we can guarantee to decompose it into QΛQᵀ where Q is an orthogonal matrix and Λ is a diagonal matrix.
Properties of singular and non-singular matrix
Let's review some of the properties of a singular n × n matrix A:
- It is not invertible.
- Its determinant equals zero.
- Columns/rows are linearly dependent.
- It has less than n pivots, i.e. it has at least one all-zero row for its variables after the row elimination.
- It has an eigenvalue equals zero. From the eigenvalue definition, if the eigenvalue λ is zero, det(A) = 0 and therefore, it is singular. (We will discuss eigenvalue later.)
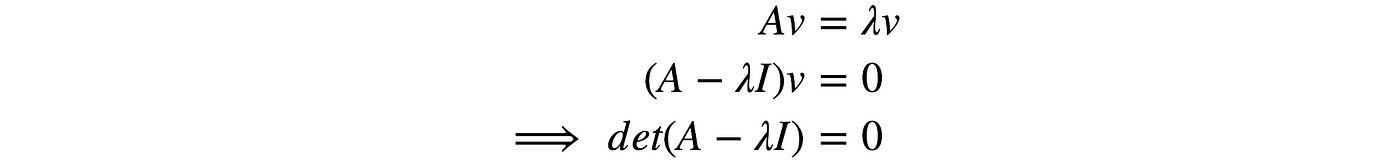
Let's summarize the difference between a singular and non-singular n × n matrix.

Basis
A basis for a vector space is a series of linearly independent vectors that span this space. Different basis can have different vectors. But all bases have the exact same number of vectors (not too few and not too many). n linearly independent vectors are needed to form a basis for Rⁿ. The dimension of a subspace equals the number of linearly independent vectors that span this subspace. After performing row elimination, all the pivot rows/columns can be used to form a basis for the row/column space of A . The n - r special solution for Ax=0 can form a basis for the nullspace N(A).

Try not to restrict yourself into numerical space only.
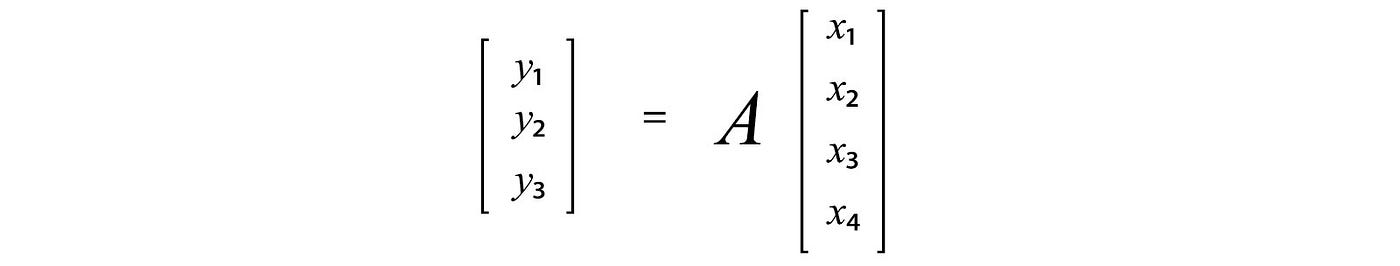
x can have a functional basis like (1, x, x², x³) and y has a basis of (x, x², x').

Matrix multiplication representation
To calculate a matrix multiplication (C=AB), we compute the element Cᵢⱼ as the dot product of the rowᵢ of A and the columnⱼ of B. However, doing this prematurely may easily get us lost in discovering the relationships between rows and columns. Let's take a border view on matrix multiplication.
The column i of the multiplication result of AB is the multiplication of A with the corresponding column i of B.

Or, the row i of the multiplication result is the multiplication of row i of A with B.
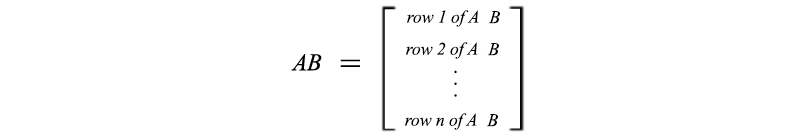
Or, the multiplication result is the sum of the multiplication of column i in A with row i in B using the outer product.
Here is an example and each term on the right below is in rank 1.

As recalled, we can also view the multiplication of a matrix and a vector as
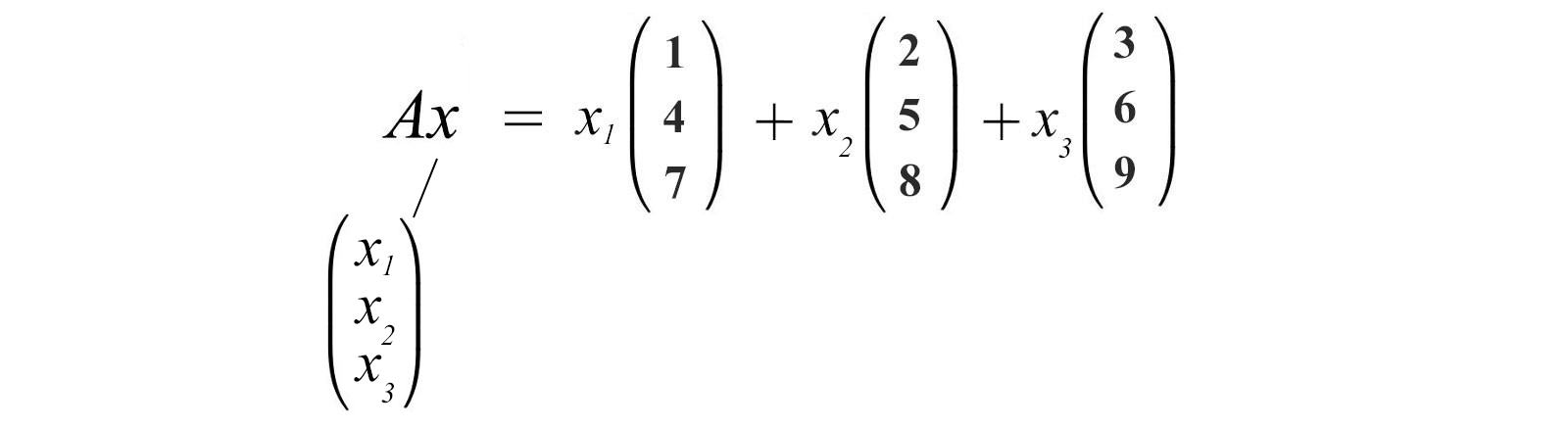
We will not elaborate further from now. But all these perspectives are important in many proofs.
Elimination, permutation, rotation, reflection matrix
In linear algebra, we can use matrix multiplication to define some matrix operations. With the new perspective on matrix multiplication, row elimination can be viewed as multiplying a matrix with an elimination matrix.

A permutation matrix swaps rows in a matrix. For each row and column, it allows only one element equals 1, others have to be 0.

A rotation matrix has the form of

A reflection matrix has the form of
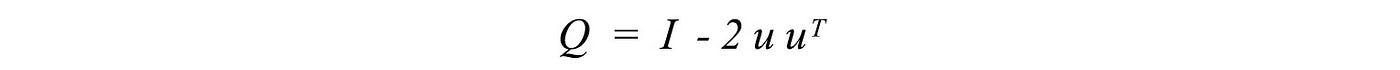
which creates a reflection along u.
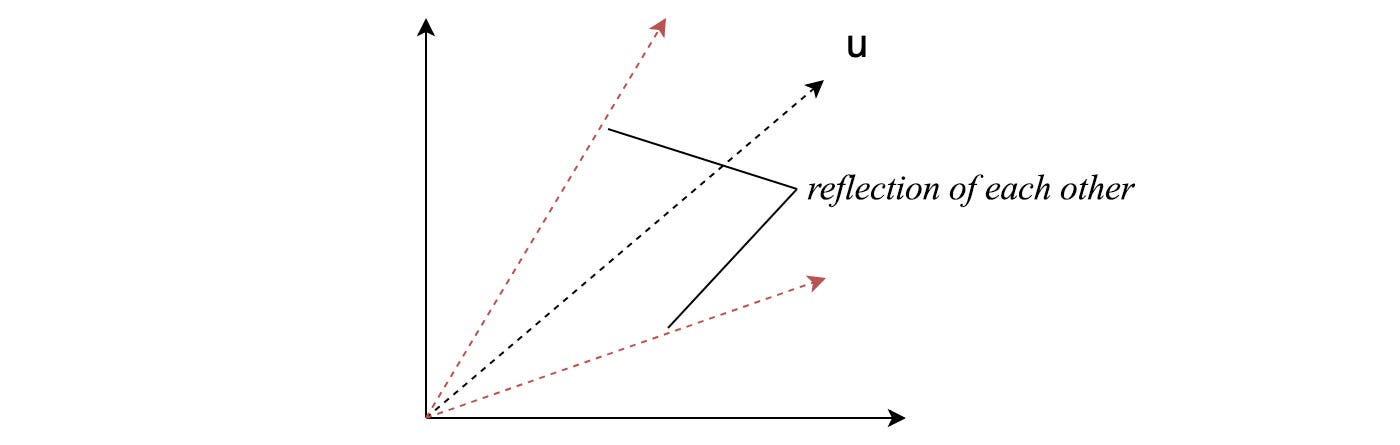
All permutation, rotation, reflection matrix are orthogonal matrices. Its inverse equals its transpose, P⁻¹ = Pᵀ.
LU factorization
As discussed, steps in the Gaussian elimination can be formulated as matrix multiplications. For example, in a 3 × 3 matrix A below, we use a matrix E₂₁ to eliminate the leading element of row 2 using row 1. The final result after all the eliminations becomes U. U is an upper triangular matrix that we use back substitution to compute the solution.
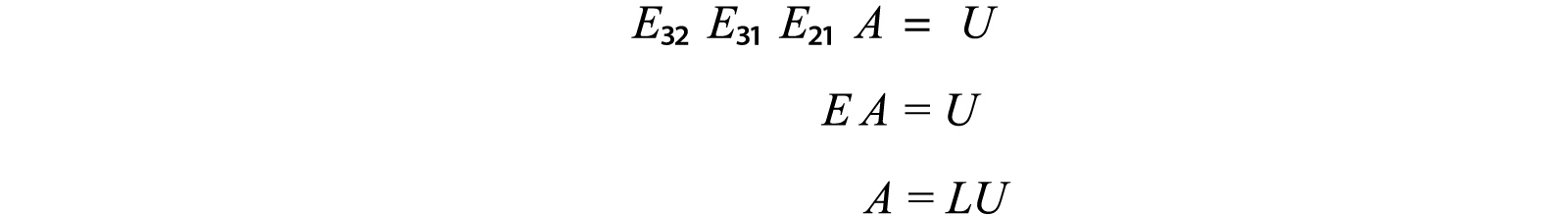
We can combine all Eᵢⱼ to form E. All Eᵢⱼ and E are all lower triangle matrices. We invert E to form L (L = E⁻¹). L is also a lower triangle matrix. The LU factorization is about factorizing A into a lower triangular matrix L and an upper triangular matrix U.
Example,
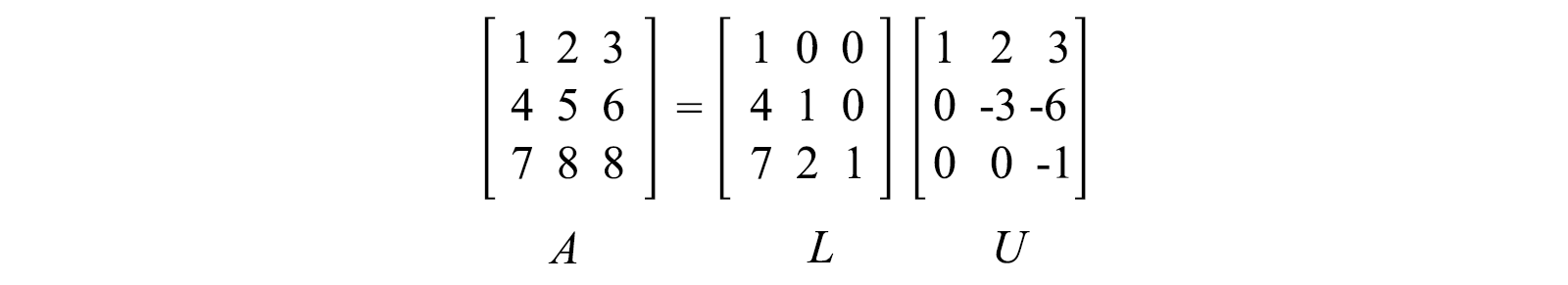
Or, sometimes we want the diagonal elements of L and U to be all ones.
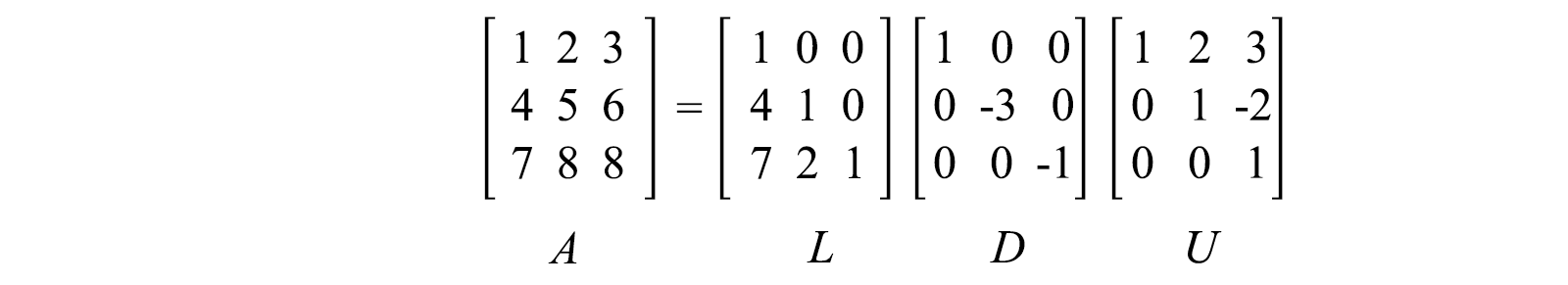
where D is a diagonal matrix with diagonal elements holding the pivots.
This is our first example of matrix factorization. They play a very important role in linear algebra. There are many other factorizations and we will introduce some of them later.
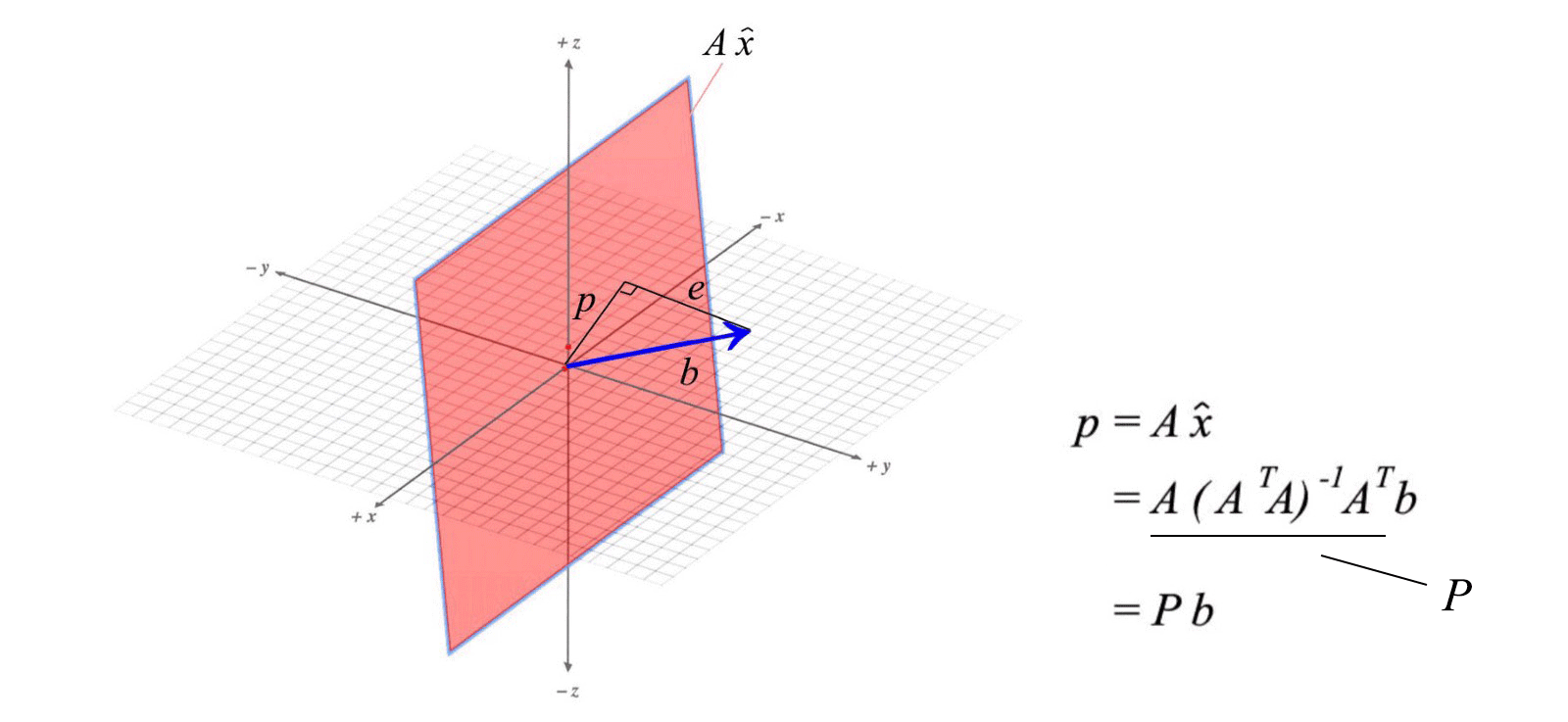
Projection
Let's review something that we may be already familiar with. In the diagram below, we project a vector b onto a. The length x̂ of the projection vector p equals the inner product aᵀb. And p equals
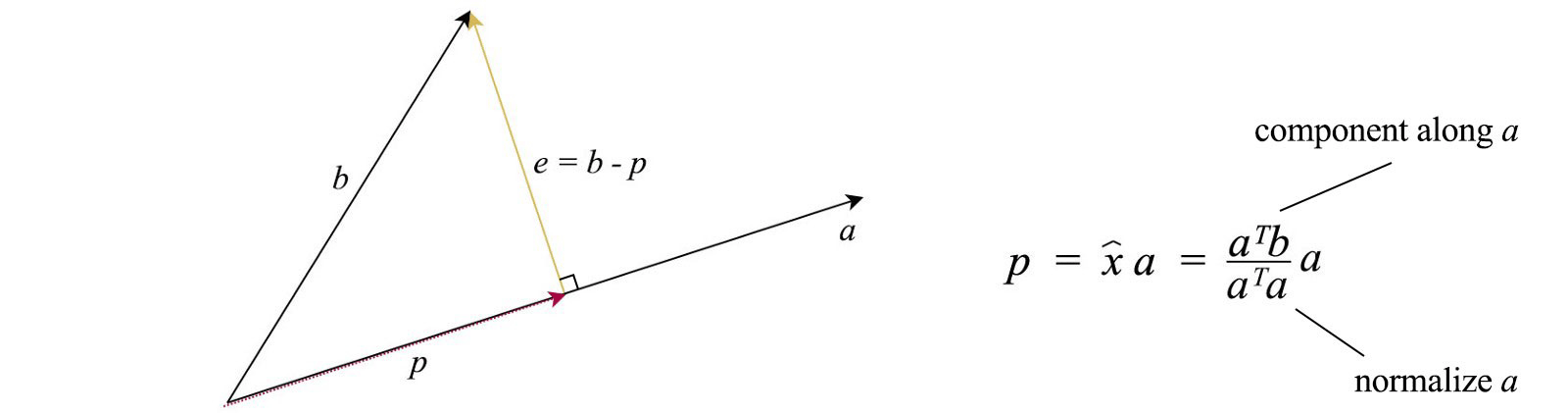
e is perpendicular to p and connects p and b together. In one perspective, projection tries to minimize this vector e that can be viewed as an error vector. Now come to a harder problem. For a multi-dimensional space, how can we project a vector onto the column space of A (space spans by Ax)? Let's express p with the component x̂ᵢ and the basis of A (aᵢ)
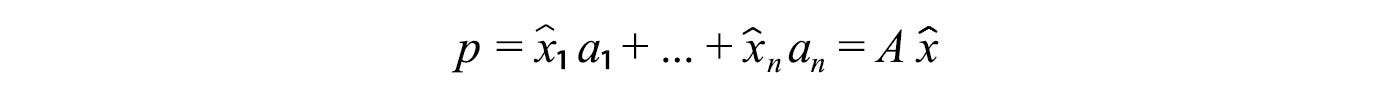
And we will model the projection with a projection matrix P
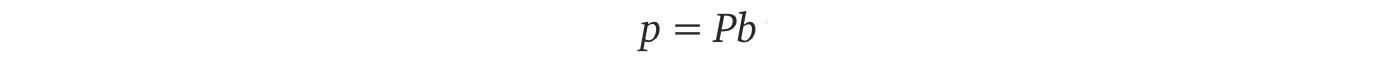
Below is the solution for P and p which can be calculated from A and b.
Proof
Since p is orthogonal to e, each vector in the basis is perpendicular to e also. We can rewrite these conditions (the left diagram below) into a matrix form.
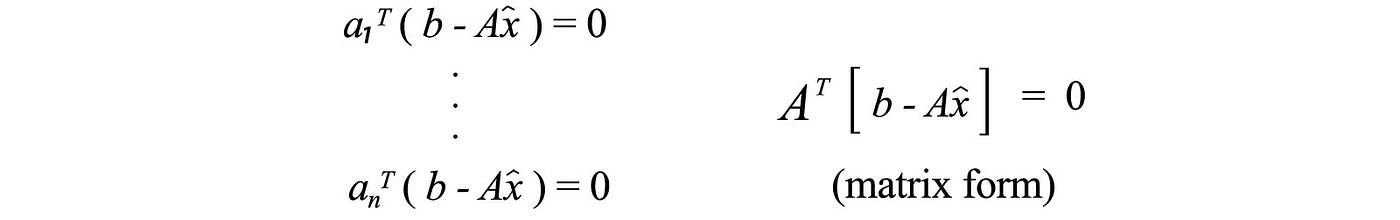
We can solve this equation and here is the solution.
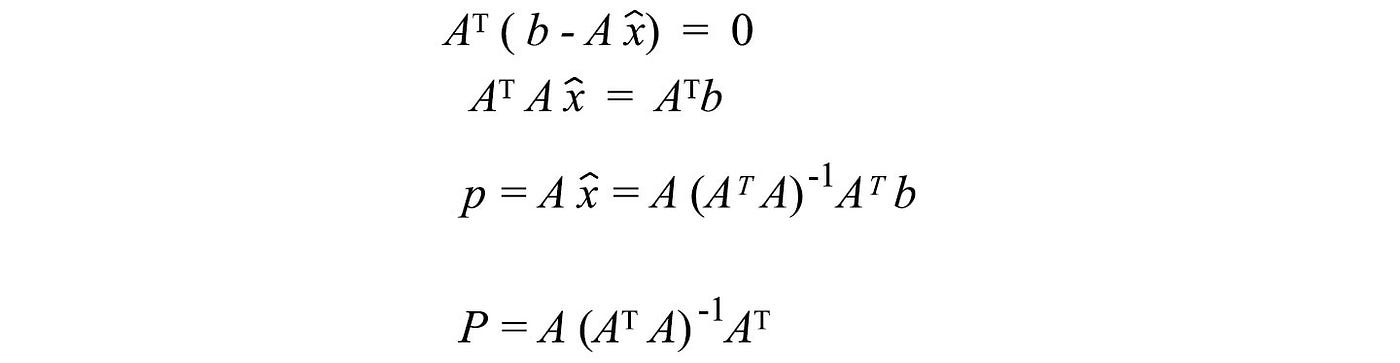
Note: We may tempt to resolve the inverse (AᵀA)⁻¹ which A(AᵀA)⁻¹Aᵀ becomes AA⁻¹ (Aᵀ)⁻¹Aᵀ and equals I. Therefore, p = b. This is wrong because (AᵀA)⁻¹ equals A⁻¹ (Aᵀ)⁻¹ only if A is invertible. This is not true for many cases. A is not invertible even for a non-square matrix.
In addition, P = P² = Pⁿ — since the projected vector is on the column space already, its projection equals itself.
Least square error
Often, it is not possible to find an exact solution for Ax=b. In ML, we want to find x with the best fit for the data, For example, we want to minimize the least square error
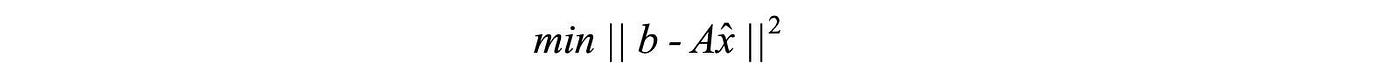
The equation above has the same objective as our projection. Recall
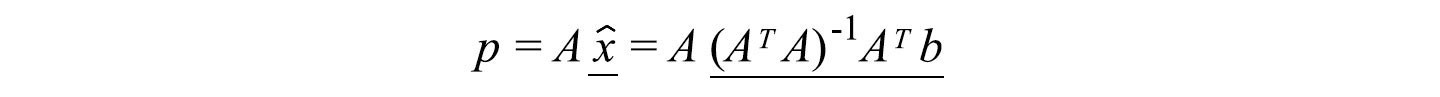
Our solution for x̂ will fulfill
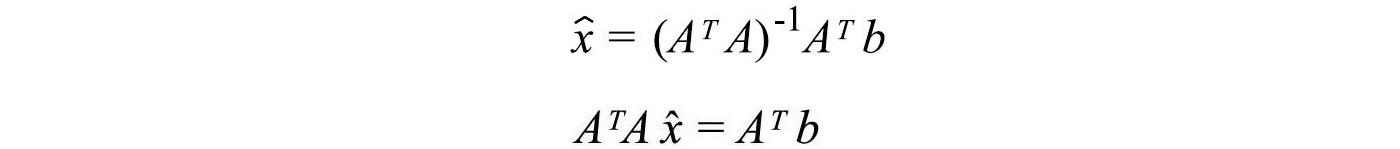
Therefore, we can use the equation above to compute x̂ using b and A. In machine learning, data is noisy. The measured or observed b has noise.
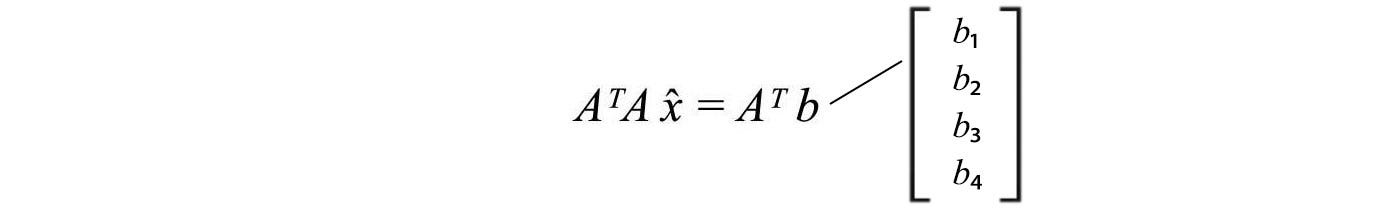
But if we know how b is distributed and how components are related, we can turn this information to make a better estimate for x̂. The covariance and variance are defined as
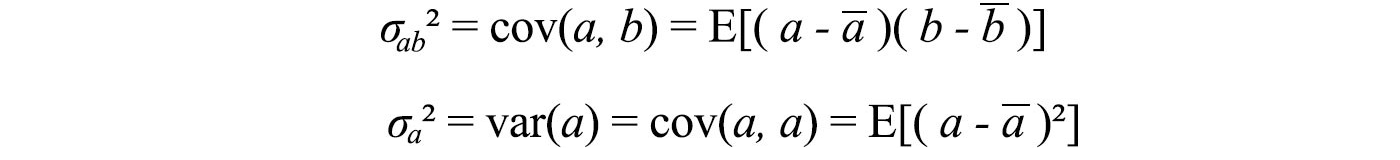
Variance measures how a property (a variable) varies while covariance is how two properties vary together. The left diagram below is the general covariance matrix. If all properties are independent of each other, all the non-diagonal elements will be zero, like the middle diagram below. The right one happens when these data are also standardized.

Equipped with the covariance matrix V for b, we can solve x̂ with
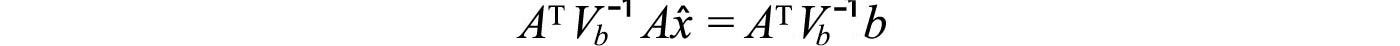
In the previous equation, the least square errors are counted equally for every dimension (property). With the new equation, V⁻¹ term whitening (standardize) the data. In other words, the error in a specific dimension with a smaller variance will carry a larger weight towards the weighted least squared error. The new equation will give a better value for x̂. In addition, the variance of the calculated x̂ will be reduced to

Let's double-check this equation again.
It resolves back to the previous equation if V = I. i.e. when all variables are standardized and not related, both equations are the same.
Gram-Schmidt process
As mentioned before, we like orthogonal matrices. For a given matrix A, the columns are unlikely orthonormal. Gram-Schmidt diagonalization helps us to find an orthonormal basis that spans the same column space of A.
Let say we have a matrix A composes of columns a, b and c. How can we find orthonormal vectors q₁, q₂ and q₃ that span the same column space of A.
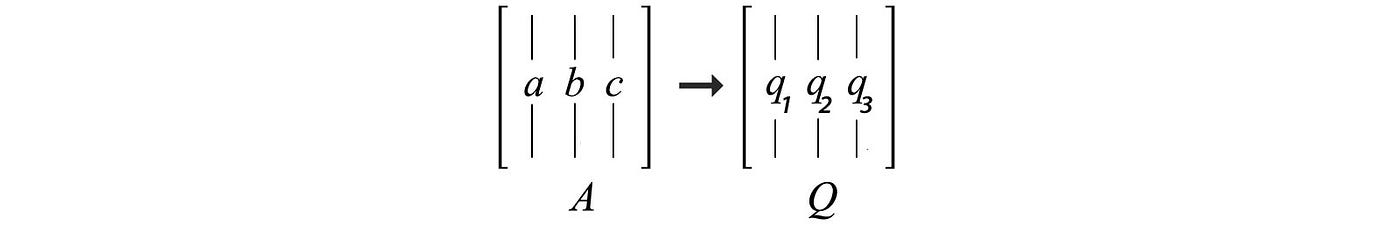
Such that we can factorize A into A = QR. We start with q₁' as a. Then q₂' equals b minus the projection of b along q₁'. Next, q₃ equals c minus the projection of c along q₁ and q₂. In short, we try to take out the projected part in the previous direction in forming orthogonal vectors.
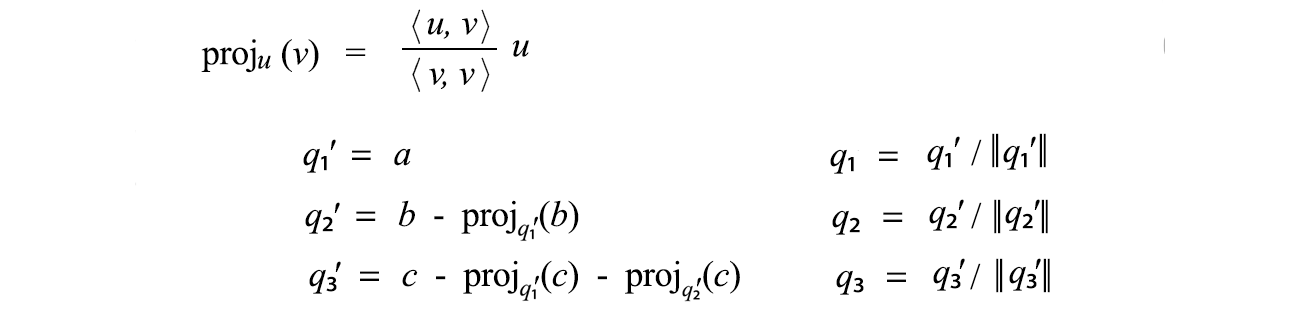
After it is done, we normalize q₁', q₂' and q₃' to form unit length q₁, q₂, and q₃. We can rewrite a, b, c as
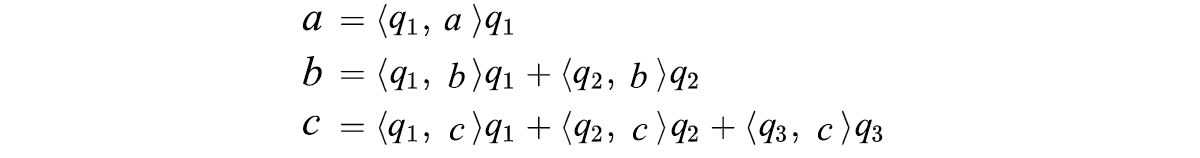
Therefore, A can be decomposed into QR with R equals
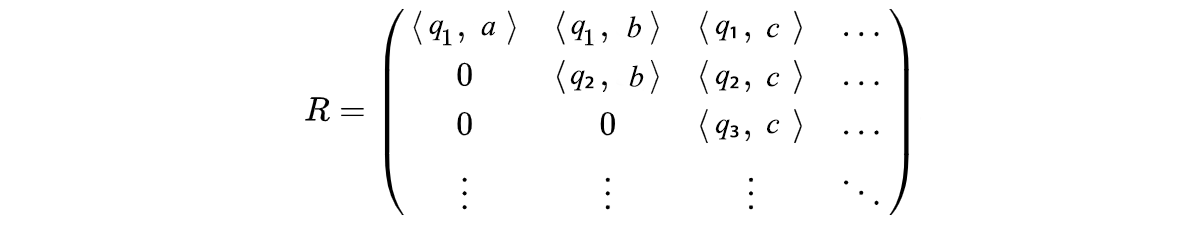
Change of basis
Consider a vector x with its basis being the column of the matrix V.

We want to transform it into a new basis, say the columns of U.
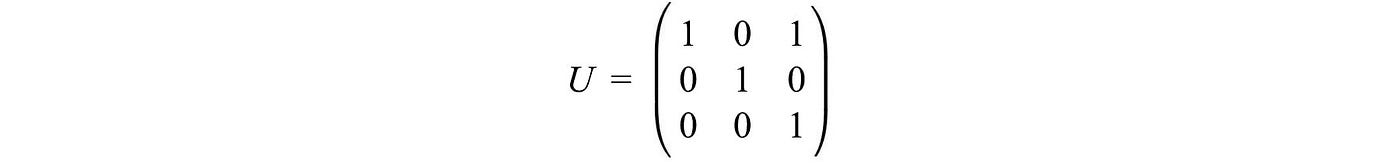
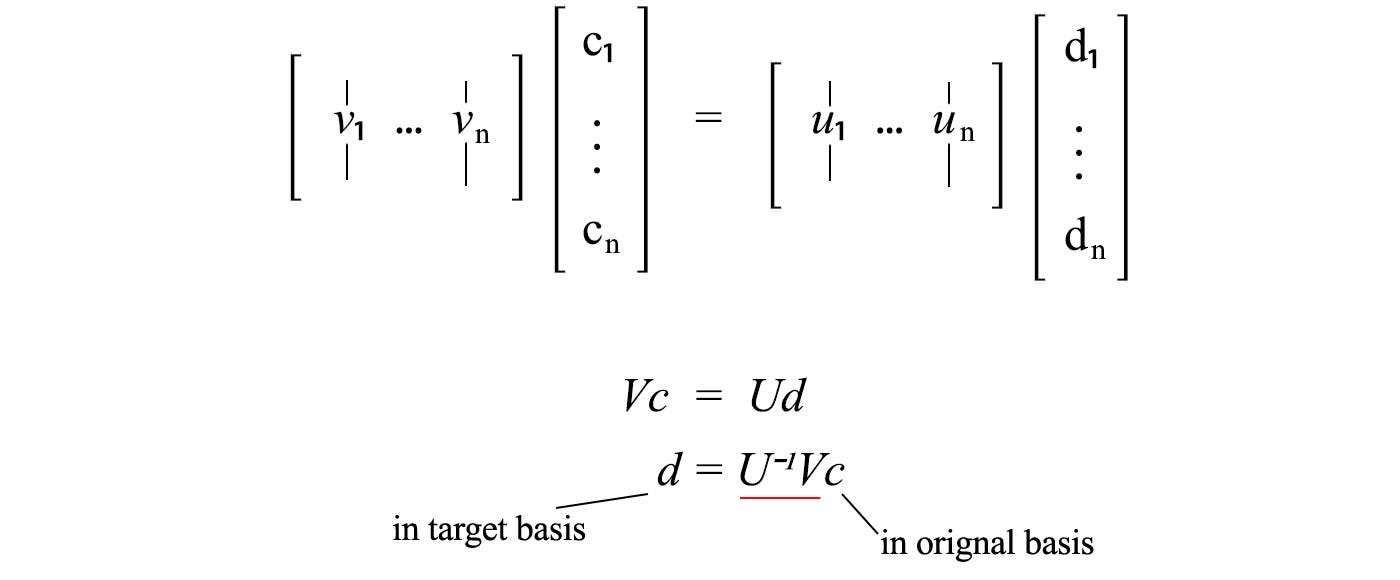
We can express the same vector in two different bases and compute the matrix needed (underline in red below) to transform the basis of a vector.
Now, let's consider the matrix P which changes the basis for x' into the basis for x. For y = Ax, the corresponding operation A' in the new basis will be P⁻¹AP.

The relation between A' and A can be written as
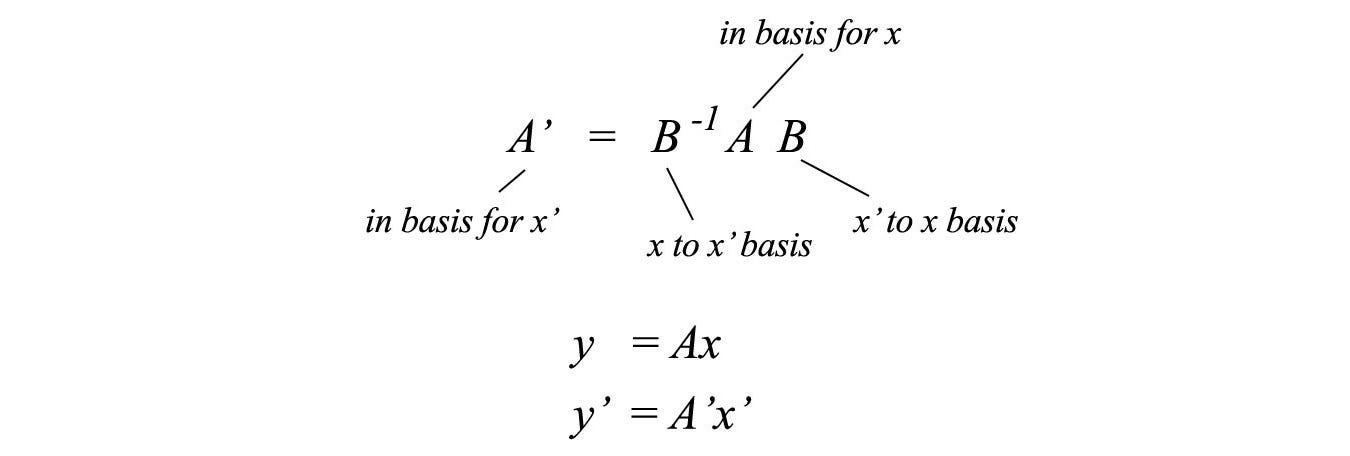
which can be further generalized as
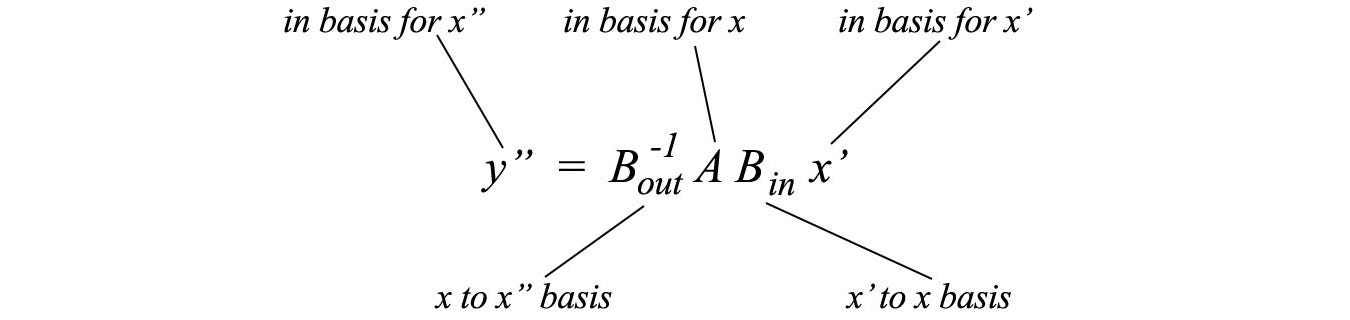
Similar matrix
Two matrices A and B are similar (A ∼ B) if
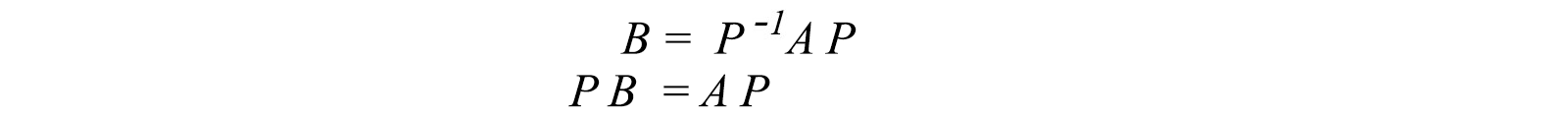
for any invertible matrix P. Given A and B, there are many possible solutions for P. If we compare the definition of a similar matrix with the change of basis, we realize that A' (with a change of basis) and A are similar matrices.
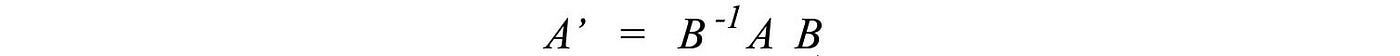
The law of physics should not be changed with a change of the reference frame (basis). So it is no surprise that similar matrics share some common properties.
Similar matrices
- have the same eigenvalues.
- the same determinant.
- the same rank, and
- both singular or both non-singular.
In linear algebra, if we can easily compute or guess a similar matrix that is much easier to manipulate, we can use it to compute the properties above instead.
Choice of basis
The choice of basis is important. The Geocentric model below uses earth as the center of reference and derive the orbits of the surrounding objects accordingly. This is chaotic and hard to find the underlining physics behind it.
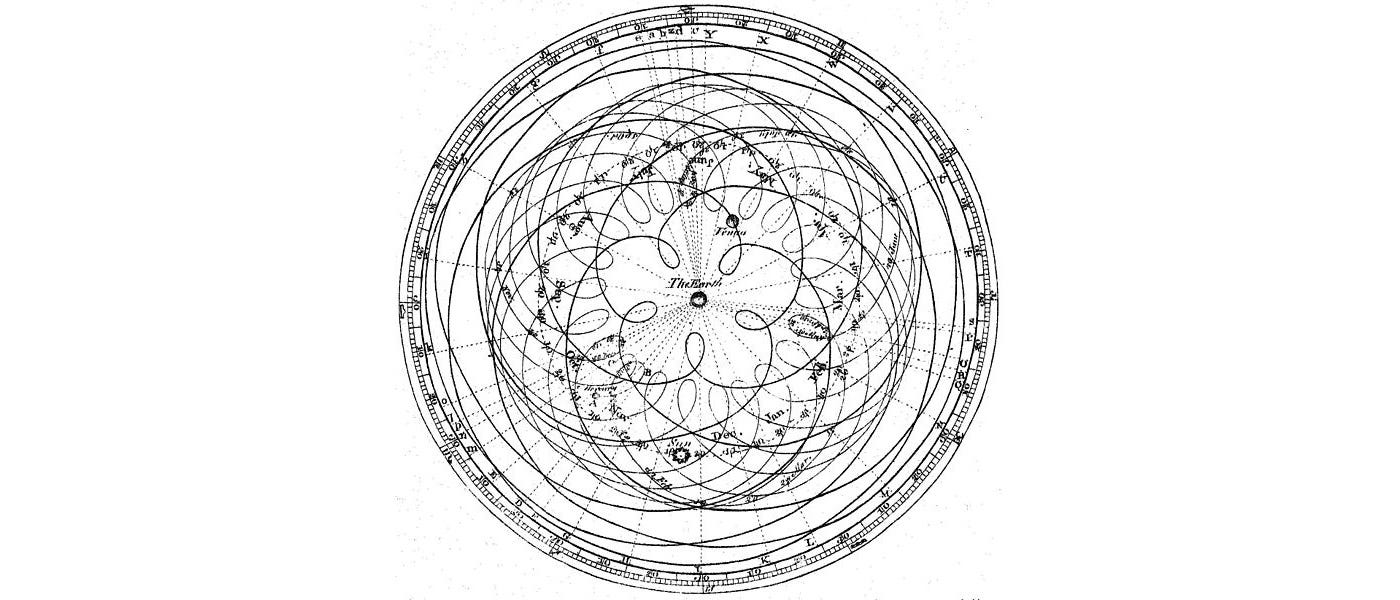
As we change the model to be centered by the sun, the model becomes much simple. This helps us to discover the fundamental theory behind the observed data. The Law of Gravity makes better sense. In later articles, we will introduce eigendecomposition and SVD. If we compare these equations, we can view those methods as a change of basis.
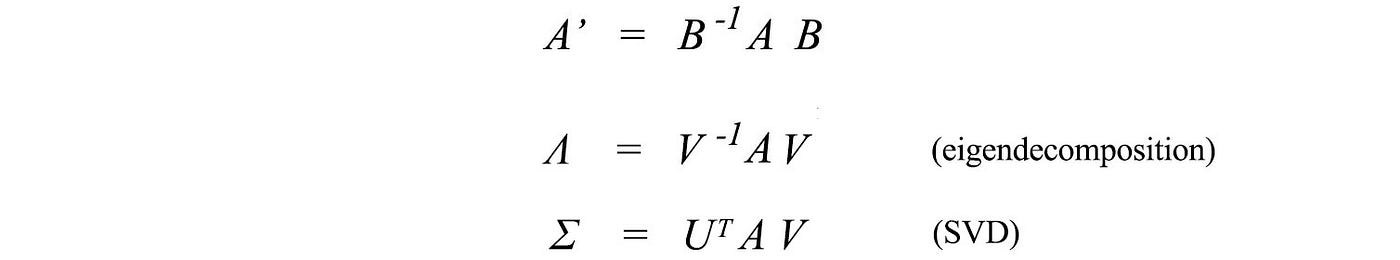
This is great news because the matrices (Λ and Σ) that are transformed into are diagonal matrices — much simple to analyze and to manipulate than A. Such simplicity helps us to discover the structures of the information.
Jordan form
Matrices can be transformed into the Jordan form which is a band matrix rather than a diagonal matrix.
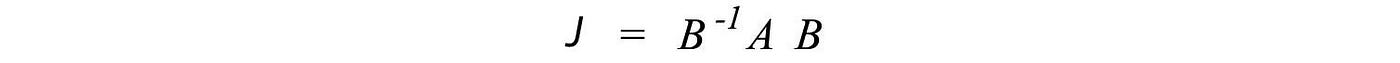
A Jordan form matrix composes of Jordan blocks of different sizes. Each block contains one of the eigenvalues as the diagonal elements and the element on the right of the eigenvalue must be one.
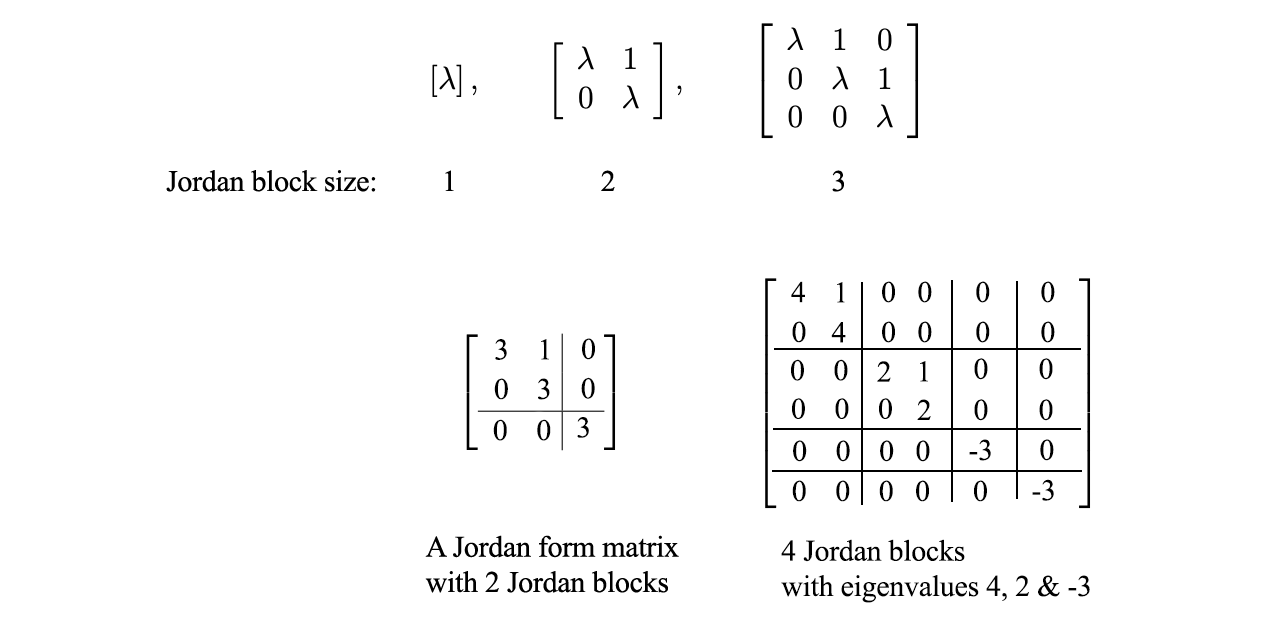
However, small changes in A create large changes in the Jordan form. Hence, it is not numerical stable in practice. Therefore, we will just let you aware of this possibility but will not elaborate further on how it can be done.
Quadratic form equation in Matrix
A quadratic equation can be written as:
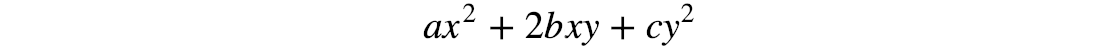
The matrix form for a quadratic equation is:
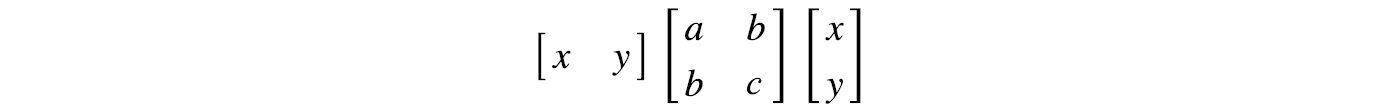
For three variables:
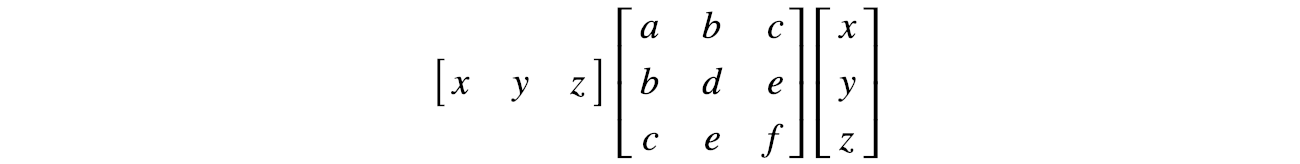
This representation is important because the cost function in ML, like the mean square error, is often expressed as a quadratic equation. Consider
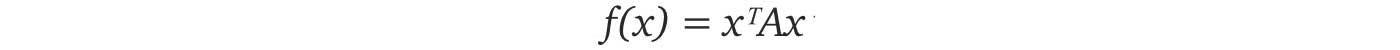
When x equals to the eigenvector of A, f equals to its corresponding eigenvalue. If x is a unit vector, the quadratic equation f(x) = xᵀAx will have the maximum and the minimum value equals to the maximum and the minimum of the eigenvalues λ of A.
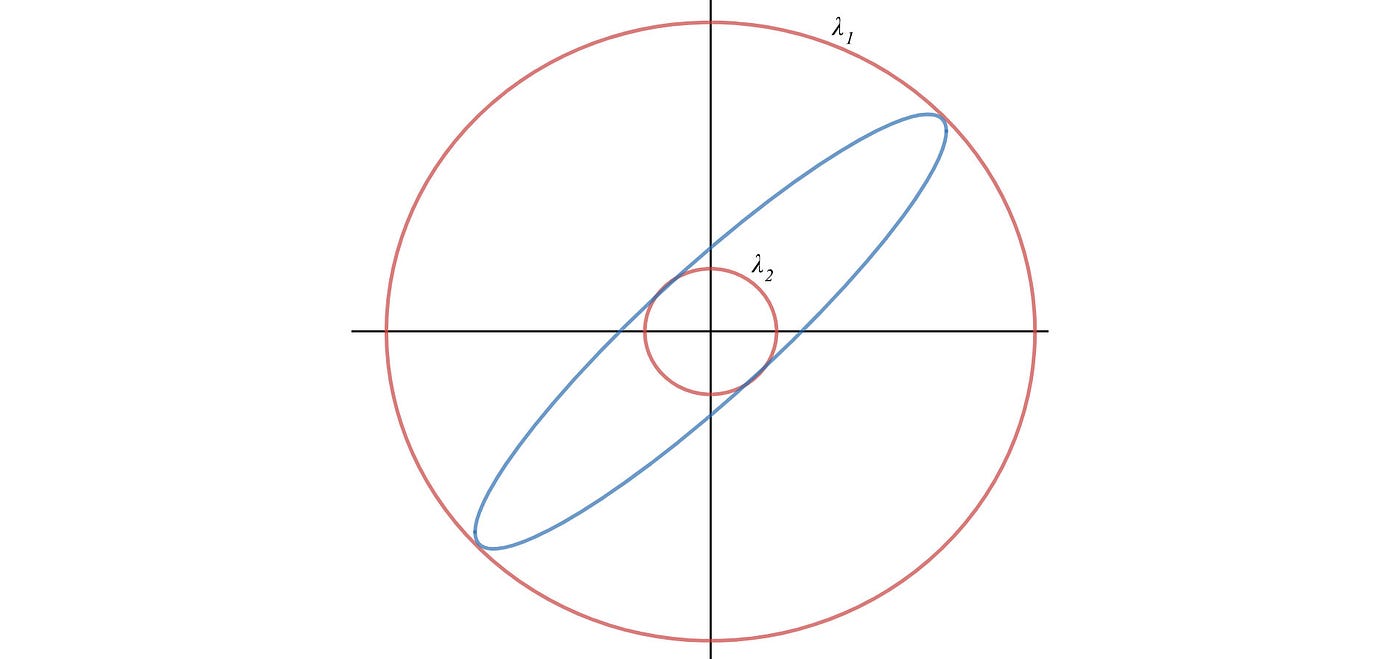
Maximum & minimum value of a quadratic function
The matrix A in representing the quadratic equations here is symmetrical.
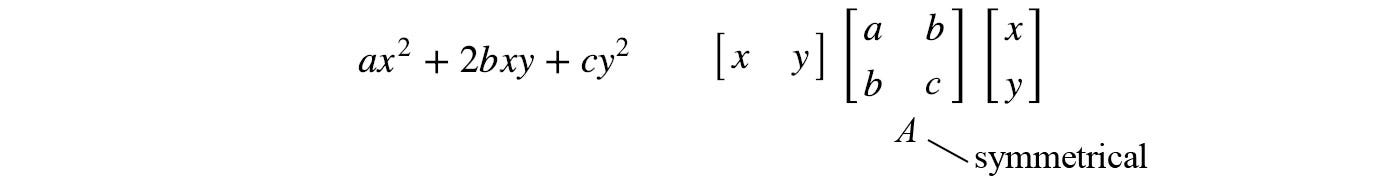
The lower and upper bound of such quadratic functions equals the minimum and the maximum of the eigenvalues of A respectively.
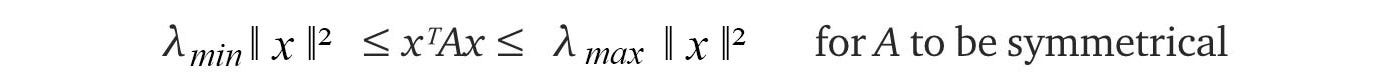
Here is the proof for the upper bound. If A is symmetrical, A can be decomposed as A = Q Λ Qᵀ where Q composes of the eigenvectors of A.
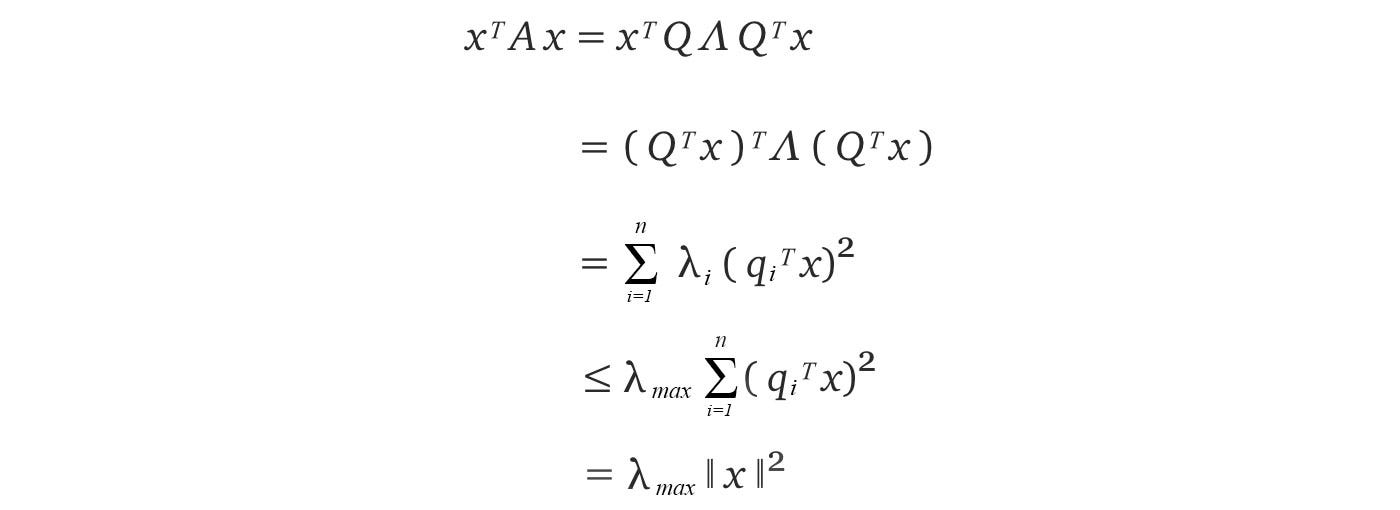
Determinant
The determinant of a 3 × 3 matrix is:
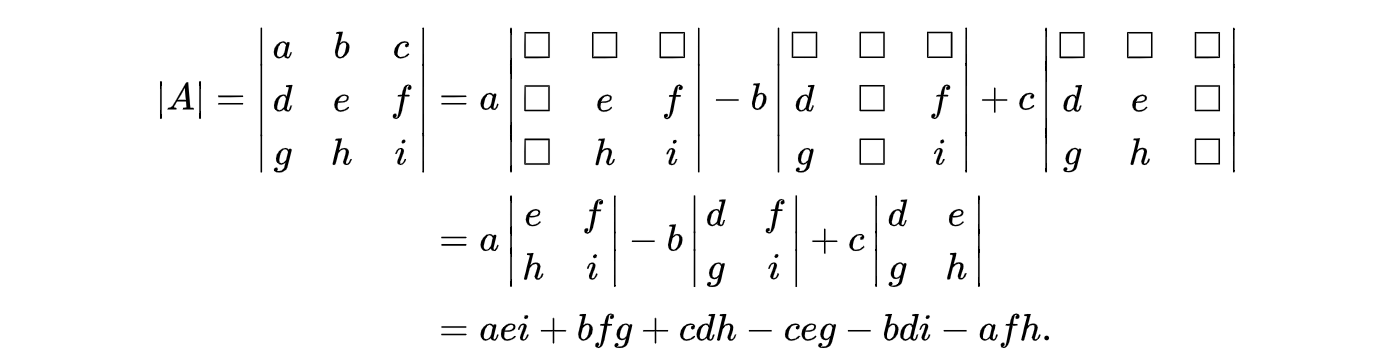
This definition can be extended to calculate the determinant of an n × n matrix recursively. Alternatively, it can be computed visually as:
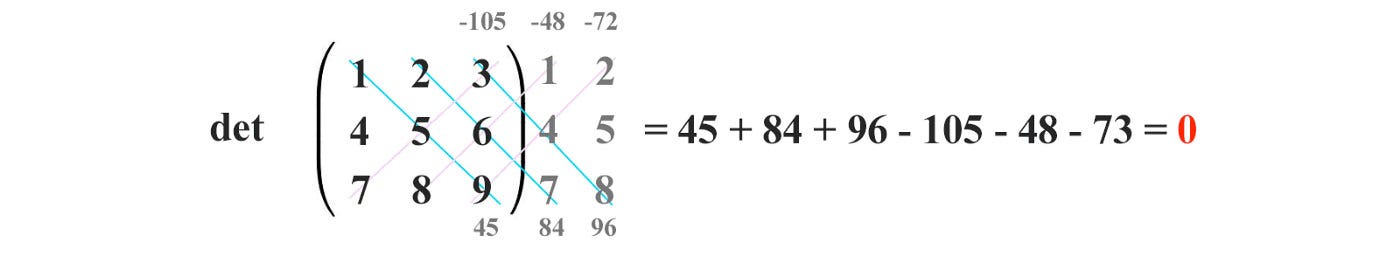
Properties

If the absolute value of the determinant for A is greater than 1, Ax expands the output space. If it is between 0 and 1, it shrinks the space. This is important in understanding the stability of the system.
Norm
Deep learning uses norms to compute errors or to perform regularization. Here are different types of norms.
L1-norm (Manhattan distance):
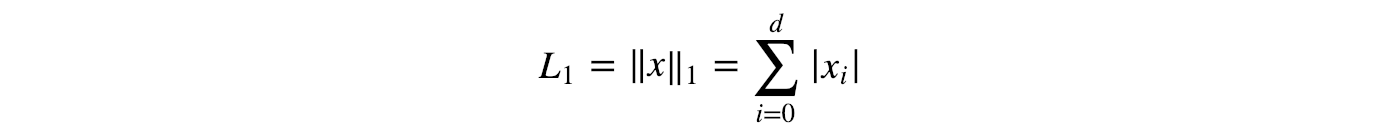
L2-norm
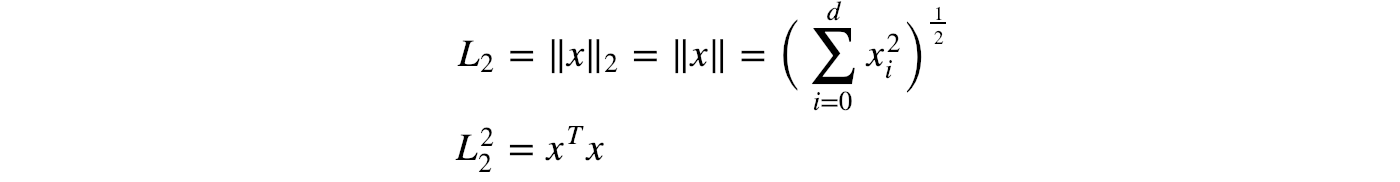
Lp-norm
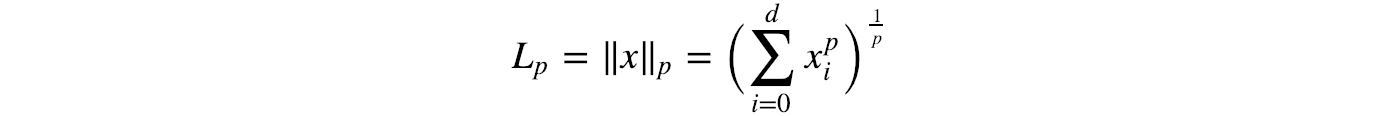
Max-norm
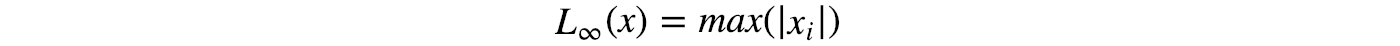
Frobenius norm
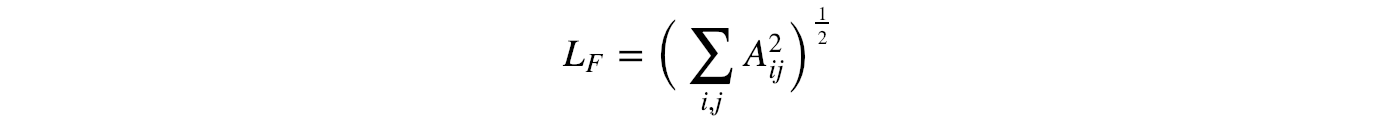
Comparing L1 & L2-norm
Comparing to L1-norm, L2-norm makes more dramatical changes to a model for large-value errors. This makes L2-norm vulnerable to outliners and less robust. In addition, L1-norm promotes sparsity in model weights. It is desirable for many machine learning problems. However, the gradient change is smoother in L2-norm around zero. Therefore, the L2-norm training is more stable with more gradual gradient changes. This makes L2-norm more popular in general.
Matrix norm
The norm of a matrix is the maximum growth factor of any vector x .
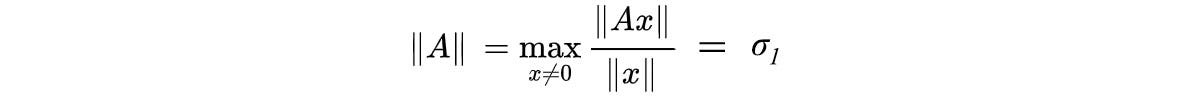
This is the same as constraining x to have a unit length.
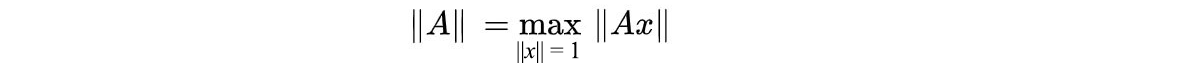
The norm can be computed as:
- If the matrix is positive definite, the norm is the maximum eigenvalue of A.
- If the matrix is symmetric, we take the absolute value of the eigenvalues and select the largest value. (Since the norm measures length, we care more about its absolute value.)
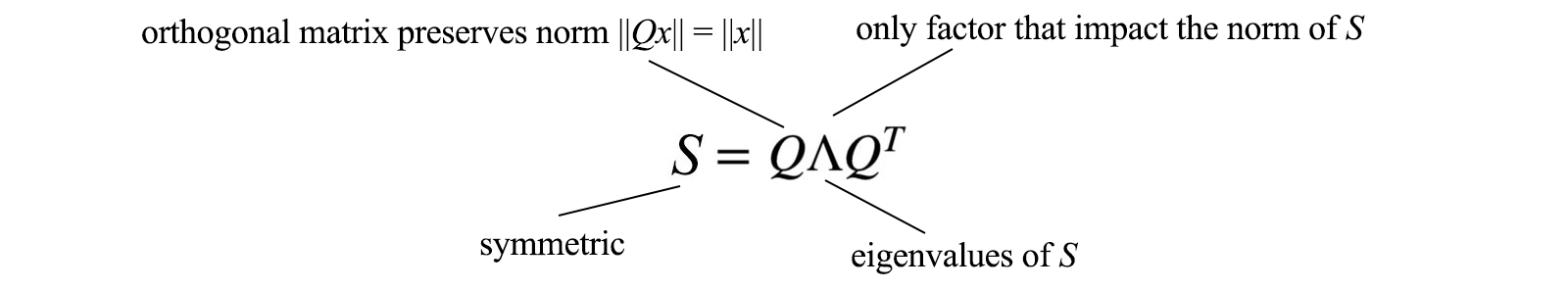
- Otherwise, it is the maximum singular value of A. i.e. the square root of the maximum eigenvalue of AᵀA.
Rayleigh quotient
Finding the matrix norm of A is the same as finding the maximum value of the Rayleigh quotient below.
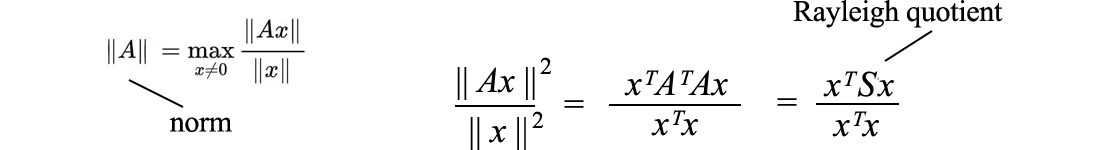
Let's rewrite the Rayleigh quotient with the inner product.
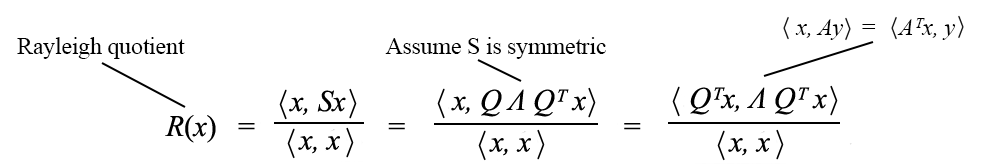
We substitute x with Qx above.
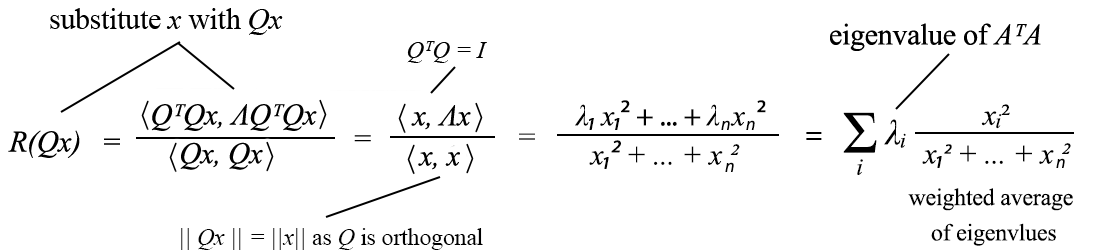
So Rayleigh quotient is the weighted average of the eigenvalues of AᵀA. Since a weighted average is smaller or equal its maximum value,
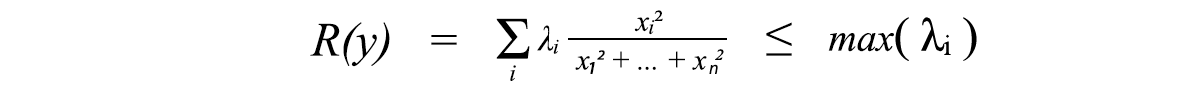
We often reshuffle λ in descending order. So λ₁ holds the largest eigenvalue. The norm of A is, therefore, the root of the largest eigenvalue of AᵀA (the singular value σ₁ of A).
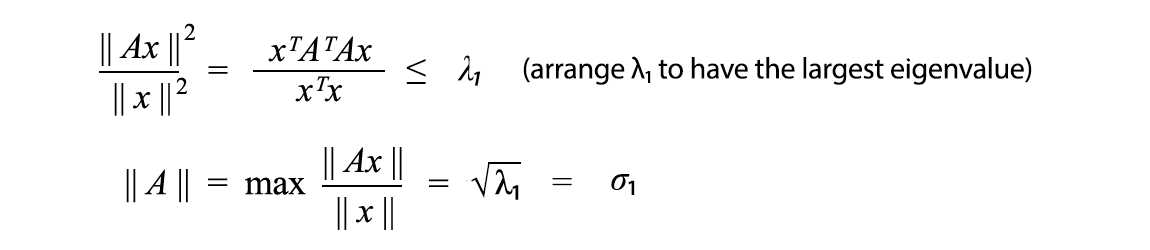
For a symmetric matrix S,

Condition number
In linear algebra, we use a condition number to track how sensitive the output is depending on errors in the input. The accuracy of the elimination method is reflected by the condition number
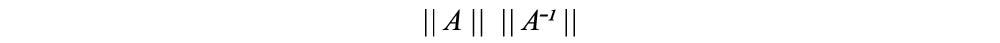
Trace
The trace is the sum of the diagonal elements of A. It can be used to verify eigenvalues and also shows up in many proofs.
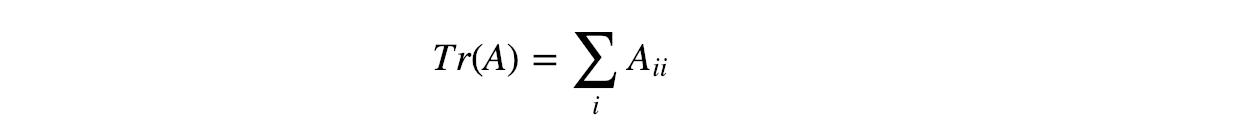

Property
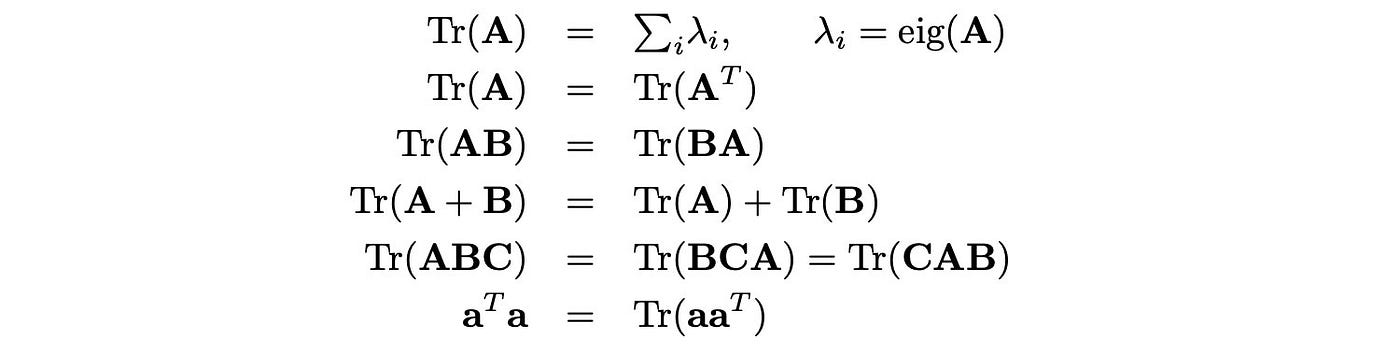
Element-wise matrix operation
Hadamard product produces a matrix with element i, j equals the product of elements i, j of the matrix A and B.
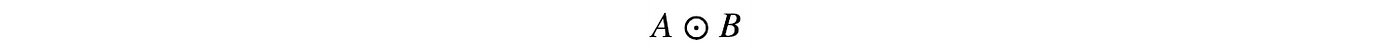
Reference
Introduction to Linear Algebra by Gilbert Strang
The Matrix Cookbook by Kaare Petersen & Michael Pedersen
Linear Algebra by Georgi E. Shilov
Deep Learning by Ian Goodfellow, Yoshua Bengio, Aaron Courville
Differential Equations and Linear Algebra (MIT Open Courseware)
Thoughts
So far, we have been focused on solving Ax=b and introducing basic concepts. Next, we will study a simple concept Av = λv which turns out to be the master key in solving many problems.
Find Particular Solution for Ax V W
Source: https://jonathan-hui.medium.com/machine-learning-linear-algebra-a5b1658f0151